





Давайте разберёмся, что представляет из себя Data Science и как построить карьеру в сфере работы с данными.
Что такое Data Science
Data Science — наука о данных и их анализе. Сфера охватывает сбор больших массивов структурированных и неструктурированных данных и преобразование их в человекочитаемый формат. Преобразование включает в себя визуализацию, работу со статистикой и аналитическими методами — машинным и глубоким обучением, анализом вероятностей и построением предиктивных моделей, построением нейронных сетей и их применением для решения актуальных задач.
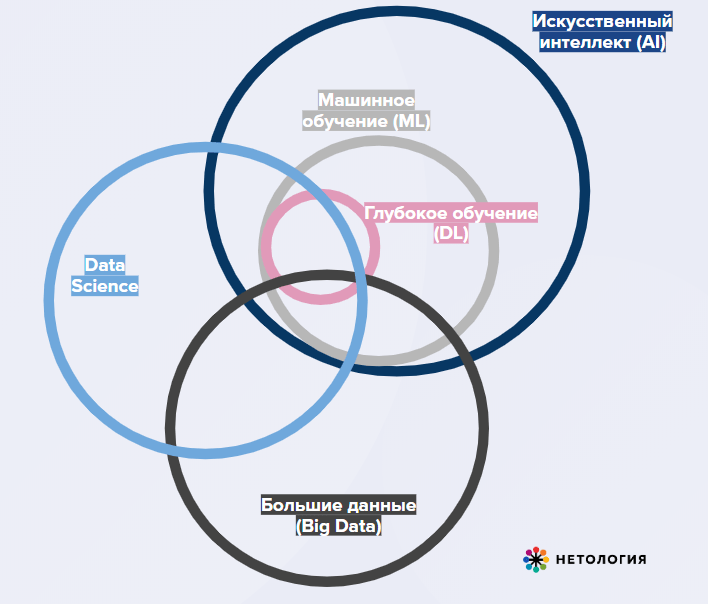
Начнём с определения терминов.
Искусственный интеллект — обучение машин «думать» для упрощения рутинных процессов и освобождения людского ресурса для творческих задач. Используется в персонализации, цифровых двойниках, имитации человеческого мышления, алгоритмах-игроках.
Первыми моделями ИИ считают машины Тьюринга, созданные в 1936 году. Несмотря на долгую историю, ИИ в большинстве областей ещё не способен полностью заменить человека. И соревнования искусственного интеллекта с человеком в шахматах, и шифрование данных — две стороны одной медали.


Машинное обучение (Machine learning, ML) — создание инструментов для извлечения знаний из данных. Это рекомендательные системы, предсказательные (предиктивные) алгоритмы, распознавание образов, перевод картинок в текст, синтез текстов. В ML модели могут обучаться на данных самостоятельно или поэтапно: обучение с учителем, то есть наличие подготовленных человеком данных ⟶ обучение без учителя, работа со стихийными, зашумлёнными данными.
Глубокое обучение — создание многослойных нейронных сетей в областях, где нужен более продвинутый или быстрый анализ и традиционное машинное обучение не справляется. «Глубину» обеспечивает более чем один скрытый слой нейронов в сети, которая проводит математические вычисления.
Используется в дип-фейках, «масках» в приложениях, высокоточных автопилотах, синтезе изображений, голоса и звука.

Data Science — понимание и придание смысла данным, визуализация, сбор инсайтов и принятие на основе данных решений. Специалисты направления используют некоторые методы машинного обучения и Big Data — облачные вычисления, инструменты создания виртуальной среды разработки и многое другое.
Применяется для автоматизации, ускорения исследований, моделирования. Обеспечивает сочетание разных подходов и математически доказанную значимость в принятии решений.
Big Data (Большие данные) — совокупность подходов к огромным объёмам неструктурированных данных. Это данные соцсетей, медиатеки, стриминг данных, банковские транзакции, события в MMORG.
Специфика сферы — инструменты и системы, способные выдержать высокую нагрузку.

Как и где зарабатывать на данных
- Собирать и продавать данные — в соцсетях, поисковых системах, медиа.
- Обслуживать данные — в софтверных компаниях-гигантах Google, Amazon и других.
- Разрабатывать продукты c data-решениями — в компаниях, которые создают беспилотники и другую инновационную технику.
- Извлекать из данных пользу — в рекомендательных системах, сервисах прогноза погоды и других сферах, полезных рядовым пользователям.
Самая обширная сфера — извлечение пользы из данных. Она охватывает:
- обнаружение аномалий — аномального поведения клиентов, мошенничества;
- персонализированный маркетинг — персональные email-рассылки, ретаргетинг, рекомендательные системы;
- прогнозы метрик — показателей эффективности, качества рекламных кампаний и других направлений деятельности;
- скоринговые системы — обрабатывают большие объёмы данных и помогают принять решение, например, о выдаче кредита;
- базовое взаимодействие с клиентом — стандартные ответы в чатах, голосовые помощники, сортировка писем по папкам.
Из чего состоит аналитика данных
Сбор. Поиск каналов, где можно собирать данные, и способов их получения.
Проверка. Валидация, отсечение аномалий, которые не влияют на результат и сбивают с толку при дальнейшем анализе.
Анализ. Изучение данных, подтверждение предположений, выводы.
Визуализация. Представление в таком виде, который будет простым и понятным для восприятия человеком — в графиках, диаграммах.
Действие. Принятие решений на основе проанализированных данных, например, о смене маркетинговой стратегии, увеличении бюджета на какое-либо направление деятельности компании.
Кем можно работать в аналитических проектах
Аналитики McKinsey еще в 2012 году предсказали дефицит специалистов по данным. Только в США в 2018 году нехватка составила 140‒190 тысяч человек. Недостаток менеджеров, которые могут задавать аналитикам правильные вопросы, ещё больше — 1,5 миллионов человек. Прогнозы подтвердились: специалистов действительно не хватает.
- Курсы по Data Science, аналитике данных, machine learning, SQL и Power BI
- Освоите полноценную профессию или отдельные инструменты аналитики
- Программы для новичков, опытных специалистов и руководителей
Карьерная траектория и карьерный трек
На каждом из этапов необходимо разное количество инструментов и навыков.
Есть роли и треки со схожими компетенциями (можно развиваться в одном направлении, а потом идти глубже или свернуть в другую сторону).
С точки зрения обучения это означает выкладку дорожки из кирпичиков знаний и умений – мы называем это модулями.
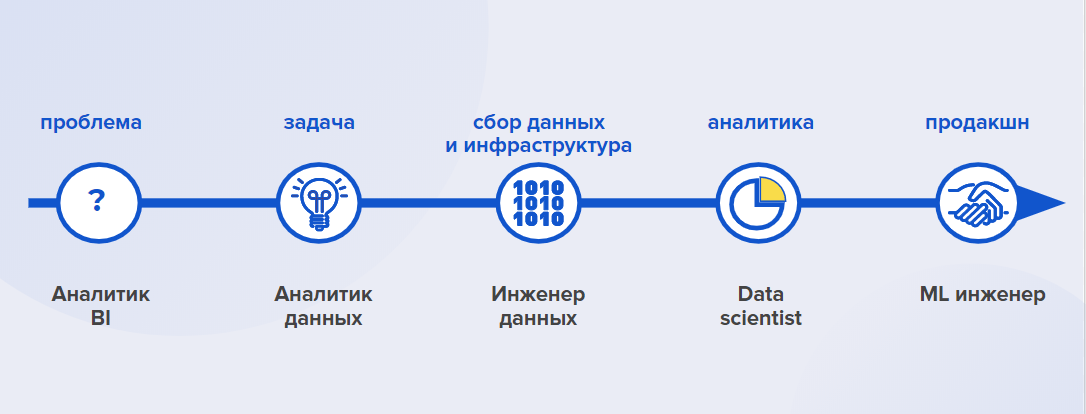
Уровень трансформации данных. ETL-специалисты преобразуют неструктурированные массивы данных в базы данных (БД):
- Data Engineer (дата-инженер) — отвечает за целостность и оптимальное хранение данных;
- разработчик БД — обеспечивает работоспособность БД;
- архитектор БД — проектирует хранение данных.
Уровень обработки данных. Анализируют собранные на предыдущем уровне данные, чтобы получить из них знание и извлечь пользу:
- Аналитик — анализирует метрики, проводит эксперименты, составляет прогнозы.
- Data Scientist — разрабатывает продукт, основанный на данных (например, рекомендательную систему).
- BI-специалист — занимается визуализацией, интерактивными дашбордами.
- ML Engineer — разрабатывает и отвечает за развитие data-driven продуктов.
Больше всего карьерных треков у ML Engineer — по сути, это разработчик алгоритмов. Это нейросети, голосовые помощники, Object detection — сфера безопасности, предсказание спроса, предиктивная аналитика, распознавание объектов. Среди более сложных направлений: GAN — работа с изображениями, RL — игровые стратегии, геймдев, Black-box AI — коробочные решения для искусственного интеллекта.
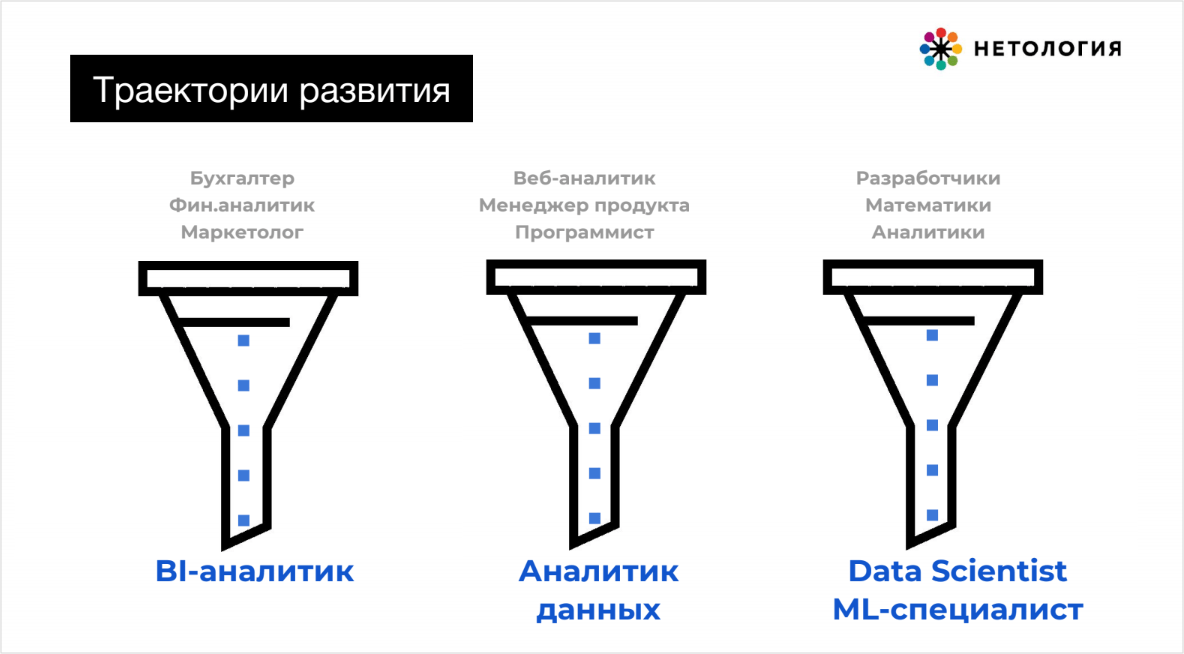
Как найти своё направление
- Учиться работать с данными и востребованными инструментами.
- Культивировать в себе исследовательский интерес.
- Не бояться называть себя «новым именем» – если занимаетесь аналитикой данных, так и пишите в CV, даже если в трудовой написано «менеджер».
- Ищите компании, в ДНК которых есть data-driven подход и желание расти кратно.
Каждый профессионал уникален, ведь у всех нас разный бэкграунд, опыт и образование.
Как разобраться в направлениях работы
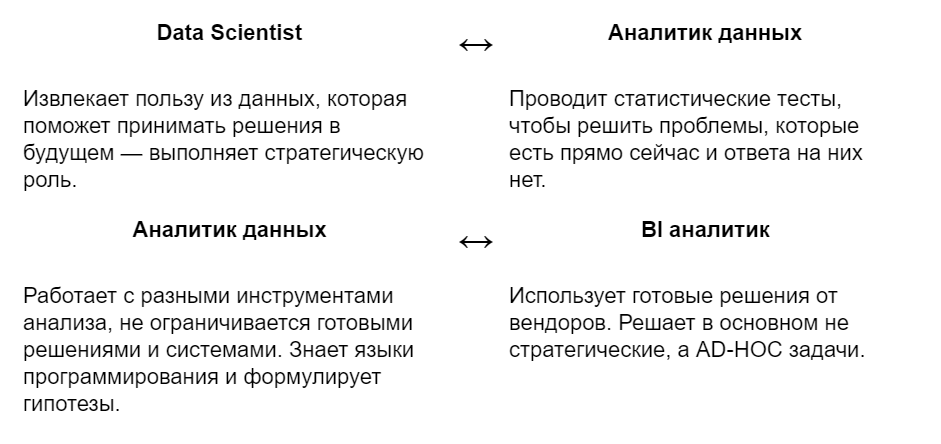

Какие знания и навыки нужны аналитику данных
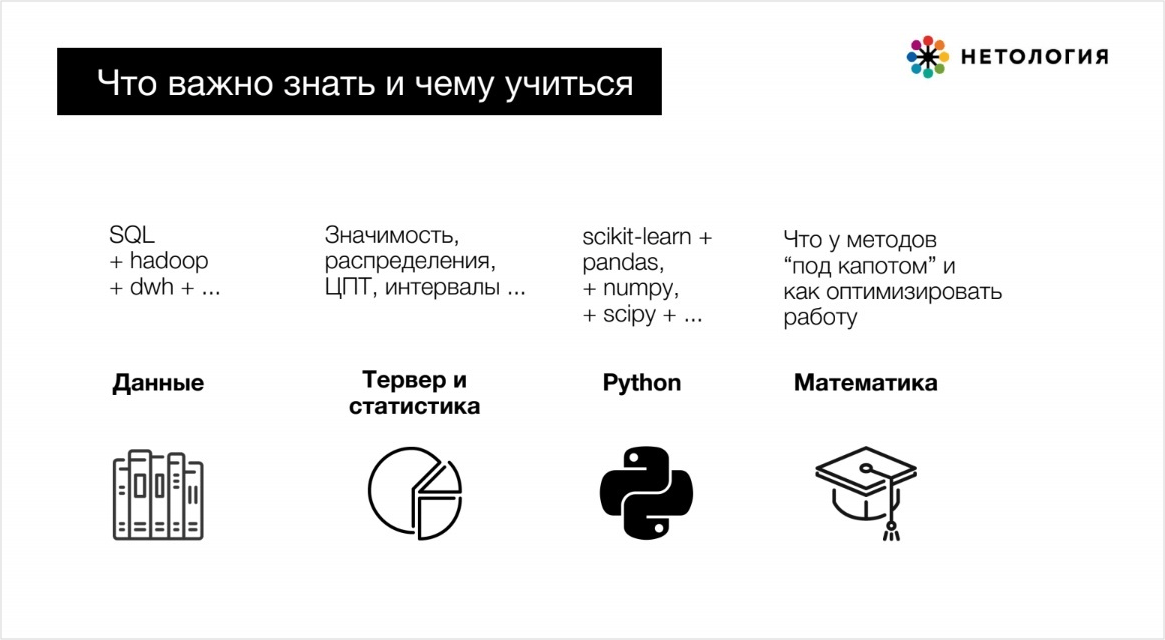
Hard skills
- Собирать и анализировать требования заказчика к решению задачи и форме его презентации.
- Получать, очищать и преобразовывать данные.
- Интерпретировать данные, делать на их основе обоснованные выводы;
- Разрабатывать требования к программным решениям и их внедрение.
- Проводить исследования и А/B-тесты.
- Знать ключевые математические методы и основы статистики.
- Делать скетчи и прототипы.
Soft skills
- Мыслить абстрактно.
- Видеть за метриками и показателями смысл.
- Находить взаимосвязи и строить гипотезы.
- Обладать развитым эмоциональным интеллектом.
Главный метанавык: выбор пути достижения цели
- Выбрать целевую компетенцию / навык (Анализ)
- Разложить на составные части (Поиск решения)
- Понять шаги для освоения и поставить дедлайн (Развитие)
- Выбрать точку приложения усилия (Внедрение навыка)
- Получить результат (Оценка)
- Повторить
ЧИТАТЬ ТАКЖЕ

Востребованные инструменты
Всем специалистам Data Science нужно освоить электронные таблицы и инструменты доступа и обработки данных: СУБД, хранилища данных, SQL, ETL.
BI-аналитику: инструменты BI — например, Power BI, Tableau, инструменты OLAP и майнинга: SAS, R, Weka, Python (ограниченно, под конкретные задачи), Knime, RapidMiner.
Data Scientist и аналитику данных: библиотеки визуализации и анализа внутри Python и R, инструменты майнинга — углублённо, интерактивные оболочки Jupyter, Zeppelin, инструменты автоматизации и развёртывания Docker, Airflow.
Data Engineer: глубокие знания ETL-процессов и выстраивания пайплайна.
Обязательно знание SQL и Python, желательно — языки Java/Scala. Нужно иметь опыт работы с облачными платформами, например Amazon Web Services или Google Cloud Platform, а также с технологиями обработки больших данных: Hadoop, Spark, Kafka.
Дерзайте меняться, а Нетология поможет!
Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.