



Алёна Игнатьева, редактор-фрилансер, написала статью специально для блога Нетологии о том, как выглядит процесс машинного обучения. Статья для конкурса блога.
Машинное обучение используется во многих областях нашей жизни — от оптимизации поиска в Google до изучения черных дыр и прогнозирования распространения раковых клеток. Поэтому когда два года назад я пришла на первую пару в университете по машинному обучению, я была уверена, что настал мой звездный час, и сейчас я начну решать задачи вселенского масштаба. Однако этого не случилось. Я с лёгкостью могла решить простенькие задачки, но понимания самого процесса у меня не было. И лишь спустя год картинка наконец-то сложилась.
Программа обучения: «Data Scientist»
Как же выглядит процесс машинного обучения изнутри? Какие шаги проходит система прежде, чем предоставить нам результат? Сможет ли система отличить пиццу от торта, если мы покажем ей, как это делается?
Предположим, нам нужно определить, видим ли мы перед собой торт или пиццу. Для того чтобы ответить на этот вопрос, нам нужна модель, которую мы построим в результате обучения.
Цель обучения — построить наиболее точную модель, которая будет правильно отвечать на заданный вопрос в большинстве случаев.
Но для того чтобы обучить модель, необходимо собрать данные для обучения. Этим и займемся.
Пицца или торт? Ищем характерные отличия
Давайте пройдемся по супермаркету и рассмотрим различные торты и пиццы. О них мы можем собрать очень много информации — начиная от формы, заканчивая количеством оливок. Для простоты возьмем два показателя: высоту в миллиметрах и содержание сахара в процентах.
Содержание сахара легко найти на этикетке, высоту можно измерить линейкой или штангенциркулем. Теперь нам нужно купить самые разнообразные пиццы и торты (чем больше, тем лучше) и прибор для измерения высоты. Как только с покупками покончено, можем начать наши измерения.
Шаг 1. Сбор данных
Первый шаг в машинном обучении — сбор данных. Очень важно правильно их собрать, так как именно качество и количество данных влияет на то, насколько хороша наша модель и насколько точным будет искомый результат.
Высокое качество данных позволяет добиться более точных результатов.
Однако, здесь важно соблюдать баланс. Не всегда огромное количество данных является преимуществом. Как правило, чем больше набор данных, тем сложнее правильно их использовать и получить нужные выводы, особенно если вы новичок в машинном обучении.
Нерелевантные данные могут снизить точность и поэтому их нужно очищать. К нерелевантным данным относятся отсутствующие значения, посторонние данные и другие данные, которые выбиваются из общего набора. И здесь есть два варианта: либо эти данные удаляются из выборки, либо заменяются на фиктивные значения. Например, пропущенные значения можно заменить на нули. Для алгоритма примерные значения работают намного лучше, чем пропущенные, поэтому тут также вопрос приоритета, что в данном случае будет важнее: точность прогноза или время, затраченное на подготовку данных.
К счастью, в нашем случае у нас достаточно данных высокого качества, и мы можем приступить к задуманному плану. Поэтому тщательно измеряем высоту, смотрим содержание сахара и записываем результат в таблицу.
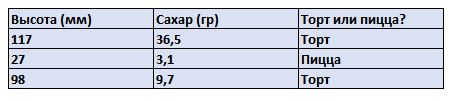
В результате мы получим таблицу с высотой, содержанием сахара и значением торт или пицца. Это тренировочные данные.
Шаг 2. Подготовка данных
После того как мы собрали тренировочные данные, можно приступать к следующему шагу — подготовке данных, когда мы загружаем данные в подходящее место и готовим их для будущего обучения.
Сначала соберем данные вместе, а затем случайным образом изменим последовательность строк для того, чтобы порядок данных не влиял на процесс обучения. Также нам нужно разделить данные на две части. Первая часть будет использоваться для обучения, а вторая — для оценки работы модели. Оптимальным будет соотношение 80/20 или 70/30. Важно, чтобы данные в этих частях не повторялись, потому что система должна обучиться, а не просто запомнить ответ на какой-либо вопрос.
Теперь данные готовы к работе, и мы можем двигаться дальше.
Шаг 3. Выбор модели
Следующим шагом будет выбор подходящей модели. Существует огромное множество моделей: какие-то из них лучше подходят для работы с картинками, какие-то — с музыкой, какие-то — с набором чисел.
При выборе модели нужно учитывать следующие параметры:
-
Точность. Не всегда требуется получить результат с максимальной точностью. В некоторых случаях будет уместно использовать приближенные значения, что позволяет значительно уменьшить время обработки.
-
Время обучения. Количество времени, необходимое для обучения модели, зависит от выбранного нами алгоритма. Как правило, чем ниже точность, тем меньше время обучения. Также некоторые алгоритмы более зависимы от объема данных, чем другие, и это может значительно повлиять на выбор алгоритма для модели, особенно, когда время ограниченно.
-
Линейность. Большинство алгоритмов в машинном обучении линейны, то есть классы данных могут быть разделены прямой линией. Для каких-то проблем линейные алгоритмы отлично работают, но в некоторых случаях могут значительно уменьшить точность, как, например, здесь:
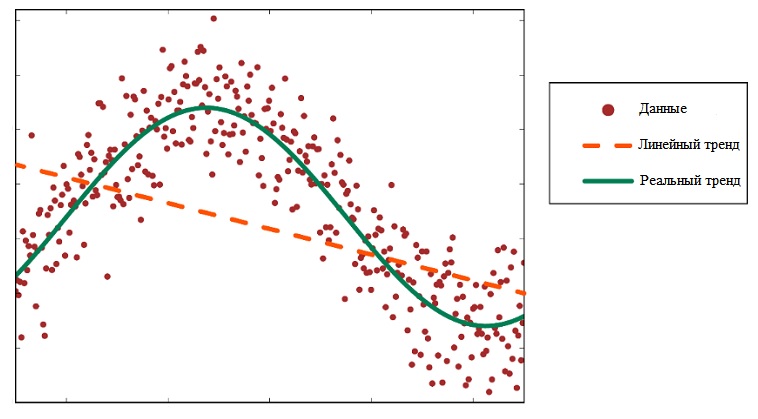
-
Количество параметров. Параметры напрямую влияют на поведение алгоритма, например, на количество итераций или чувствительность к ошибкам. Обычно, чем больше количество параметров, тем больше количество попыток и ошибок на пути к поиску наилучшего сочетания.
С другой стороны, большое количество параметров дает алгоритму большую гибкость и позволяет достичь более высокой точности.
Ниже приведены некоторые из существующих алгоритмов.
Алгоритм
Точность
Время обучения
Линейность
Параметры
Примечания
Логистическая регрессия
Высокое
v
5
Метод опорных векторов
Среднее
v
5
Хорошо работает с большими объемами данных
Нейронная сеть
Высокая
9
Дерево принятия решений
Высокая
Среднее
5
Метод k-средних
Среднее
v
4
Поскольку у нас есть всего две параметра, то можно использовать простейшую линейную модель.
Шаг 4. Обучение
Теперь перейдём непосредственно к обучению. В этом шаге будем использовать данные для того, чтобы улучшить способность модели отличать пиццу от торта.
В данном случае следует выбрать линейную модель, которая задается уравнением y=k*x+b, где x — входные данные, k — угловой коэффициент, b — точка, в которой график пересекает ось y.
В этом уравнении можно изменять только параметры k и b.
Вначале система случайным образом рисует прямую на плоскости данных и уже затем, в процессе обучения, изменяет параметры k и b так, чтобы максимально точно разделить категории.

Шаг 5. Оценка
После завершения обучения проверим, насколько хорошо работает модель. Для этого используем тестовый набор данных, которые отделили при подготовке данных для оценки работы нашей модели.
В этом шаге мы можем увидеть, как модель справляется с теми данными, которые она еще не видела, другими словами — как модель будет работать в реальном мире.
После того как мы обучили модель, проверяем её на тестовом наборе данных. Поскольку для этого набора нам известно, чему соответствует каждая пара чисел — пицце или торту, то мы можем оценить, насколько точно выбранная модель может предсказывать результат. В случае если мы не получили точного прогноза, то есть система чаще, чем хотелось бы определяет торт как пиццу и наоборот, то переходим к следующему шагу.
Шаг 6. Изменение параметров
После оценки работы модели посмотрим, можно ли её улучшить путем корректировки параметров. Возможно, мы решим, что выбранная модель не точна и возьмем другую. Также мы можем прогнать нашу модель через тренировочные данные несколько раз, чтобы улучшить точность.
В случае линейной модели, которую мы использовали, можно изменять величину шага, который использует алгоритм. Например, изначально мы решили, что параметр k — целое число, то есть алгоритм перебирал значения для k с шагом равным единице: 0, 1, 2, 3 и т. д. Но в результате мы получили не ту точность, на которую рассчитывали. Тогда мы можем уменьшить шаг до 0.5 и тогда значения k будут подбираться как 1, 1.5, 2, 2.5 и т.д. Если этого недостаточно, то можем еще уменьшить шаг. Аналогичные действия можно проводить и с параметром b.
Когда мы будем довольны полученными результатами, то сможем наконец использовать нашу модель в реальной жизни.
Шаг 7. Прогноз
Машинное обучение использует данные, чтобы ответить на поставленный вопрос. В этом шаге, применяя обученную модель, можно определить: пицца это или торт на основании заданной высоты и содержания сахара. И именно в этом шаге становится понятна вся важность машинного обучения.

Заключение
Машинное обучение может использоваться во многих сферах нашей жизни. Кто-то считает, что с его помощью можно исследовать только то, как космические корабли бороздят просторы Вселенной. Цель данной статьи — показать, что машинное обучение может быть забавным и интересным.
Читать еще: «Гид по структуре машинного обучения»
И если эта тема вам интересна, то не бойтесь и изучайте. Возможно, скоро вместо того, чтобы анализировать торты и пиццы, вы будете решать проблемы черных дыр или мирового океана. Дерзайте и всё получится!
Мнение автора и редакции может не совпадать. Хотите написать колонку для «Нетологии»? Читайте наши условия публикации.