Включает программу трудоустройства
Инженер машинного обучения с нуля
Старт в профессии и комплексные навыки: от создания до внедрения и поддержки ML-моделей. Поддержка ML-инженеров из Яндекса, Сбера, Amazon и других крупных компаний во время всего обучения

АКЦИЯ
-40%
Когда
7 августа 2026 — 23 марта 2028
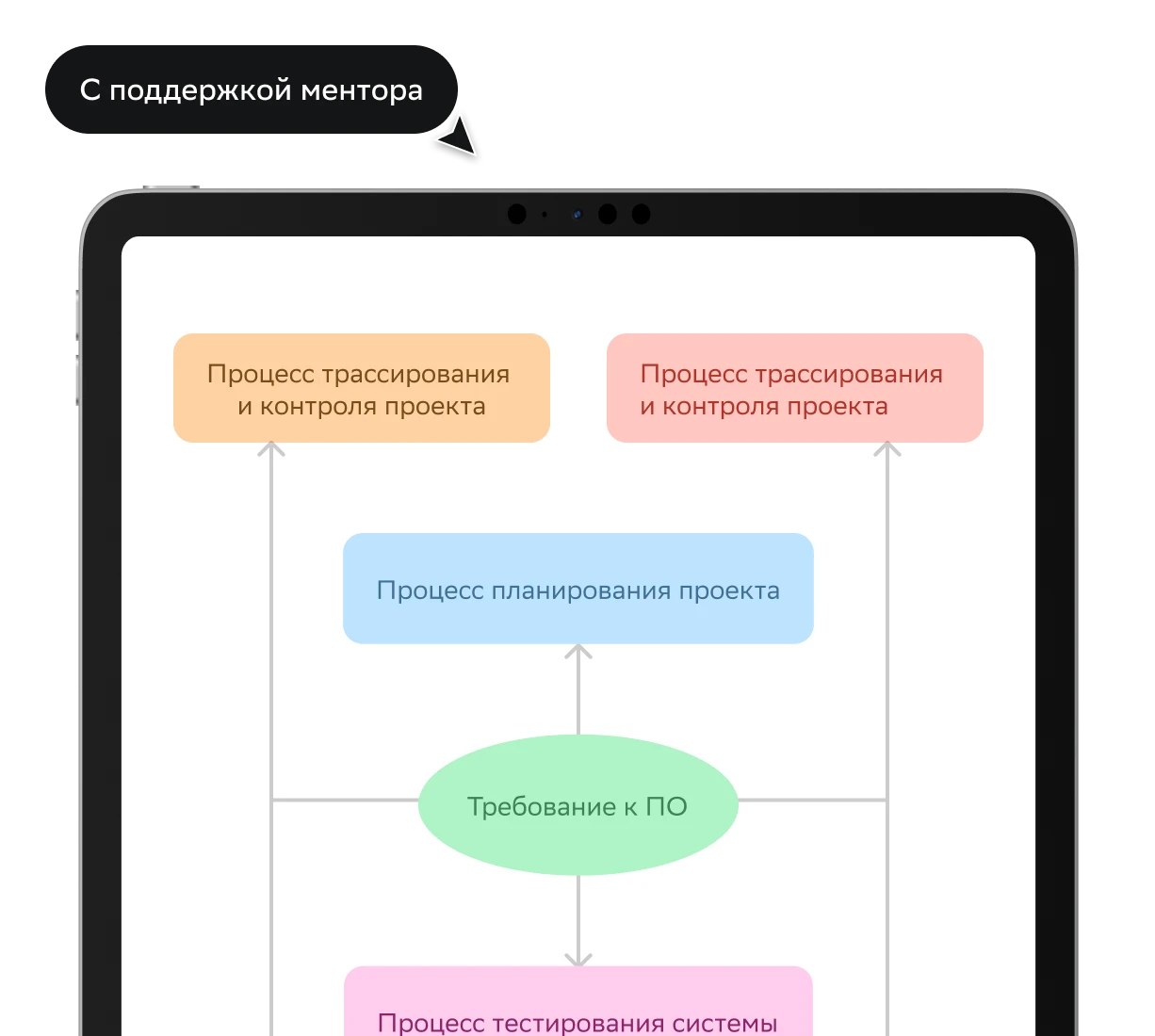
Программа
От 14 месяцев
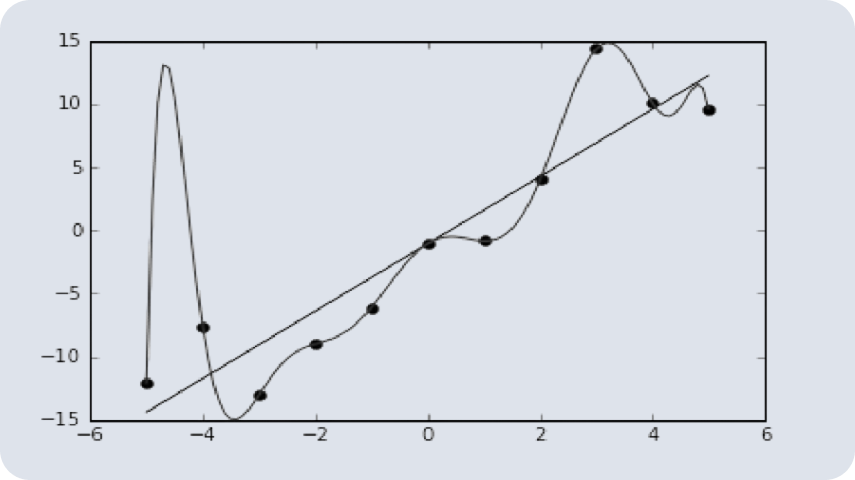
Практика
10+ проектов, задачи партнёров, диплом по своей или учебной теме
Документ
Диплом о профессиональной переподготовке
40%
с 29.07 по 31.07
Пусть лето не кончается
Цена уже со скидкой. Оплатите курс до 31 июля, чтобы сохранить выгоду.