





Редакция Нетологии собрала и кратко законспектировала самые интересные статьи по Data Science за февраль.
Обучение в онлайн-университете: профессия «Data Scientist»
«Jupyter Notebook в Netflix», habr
Сотрудники Netflix рассказали, как используют Jupyter Notebooks для быстрого прототипирования и анализа данных и как переосмысливают способы его использования — а читатели Хабра перевели оригинал статьи на русский язык.
Netflix построили гибкую и мощную платформу для работы с данными — Netflix Data Platform. Для того, чтобы упростить работу и сделать возможным поддержку широкого круга пользователей были разработаны сервисы Genie (сервис выполнения задач) и Metacat (метахранилище).
Изначально в Netflix использовали Jupyter для поддержки data science workflows, но позже осознали его универсальность для общего доступа к данным. Это позволило дать пользователям доступ ко всей платформе Netflix через Notebook.
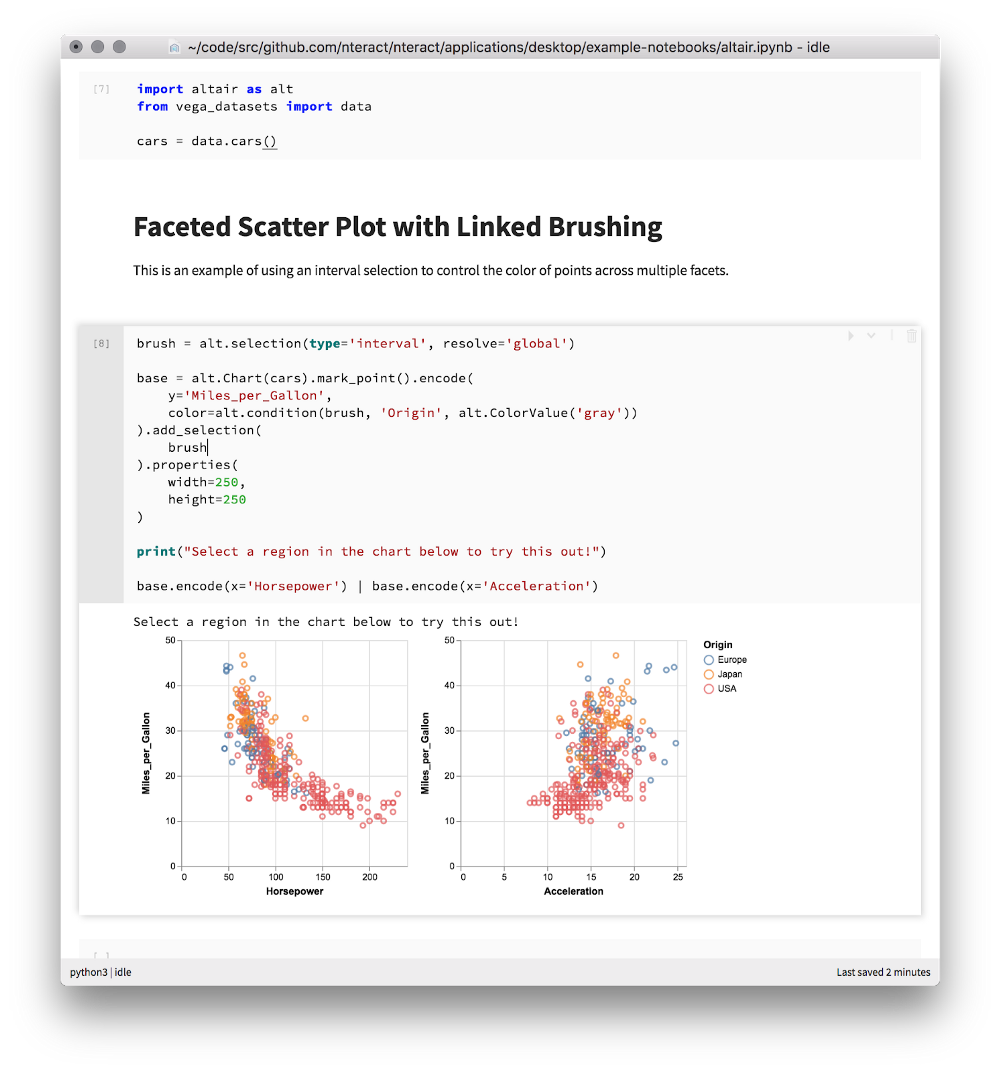
Jupyter notebook в nteract отображает Vega и Altair
Поддержка системы требует вспомогательной инфраструктуры:
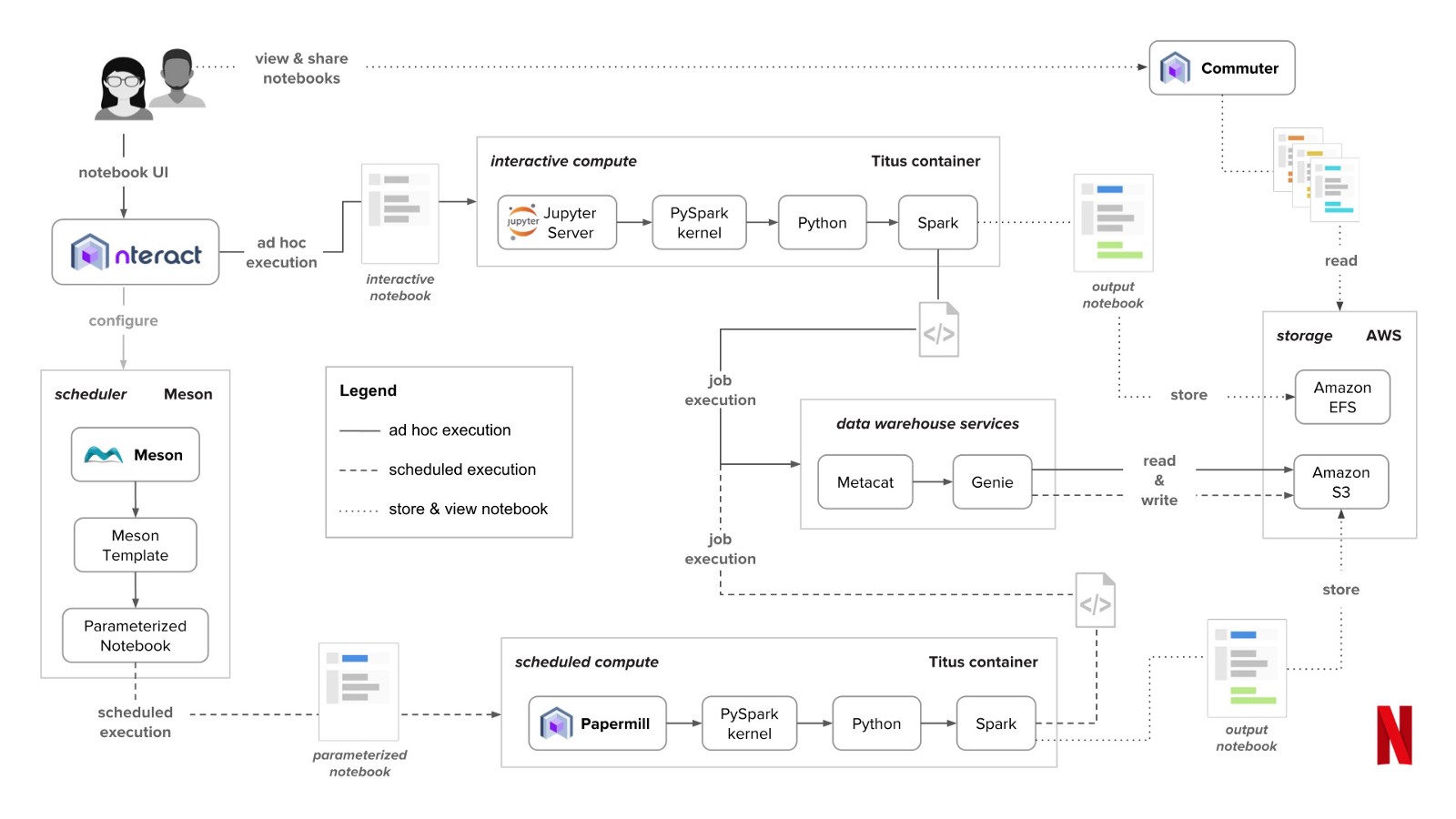
Инфраструктура Notebook в Netflix
Каждый пользователь Netflix Data Platform имеет домашнюю директорию на EFC с рабочим пространством для notebooks.
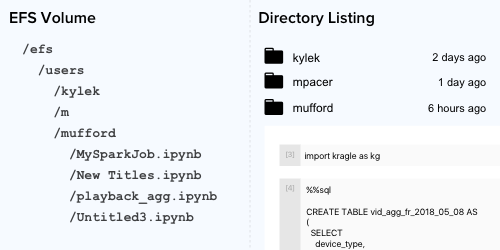
Notebook хранение vs. доступ
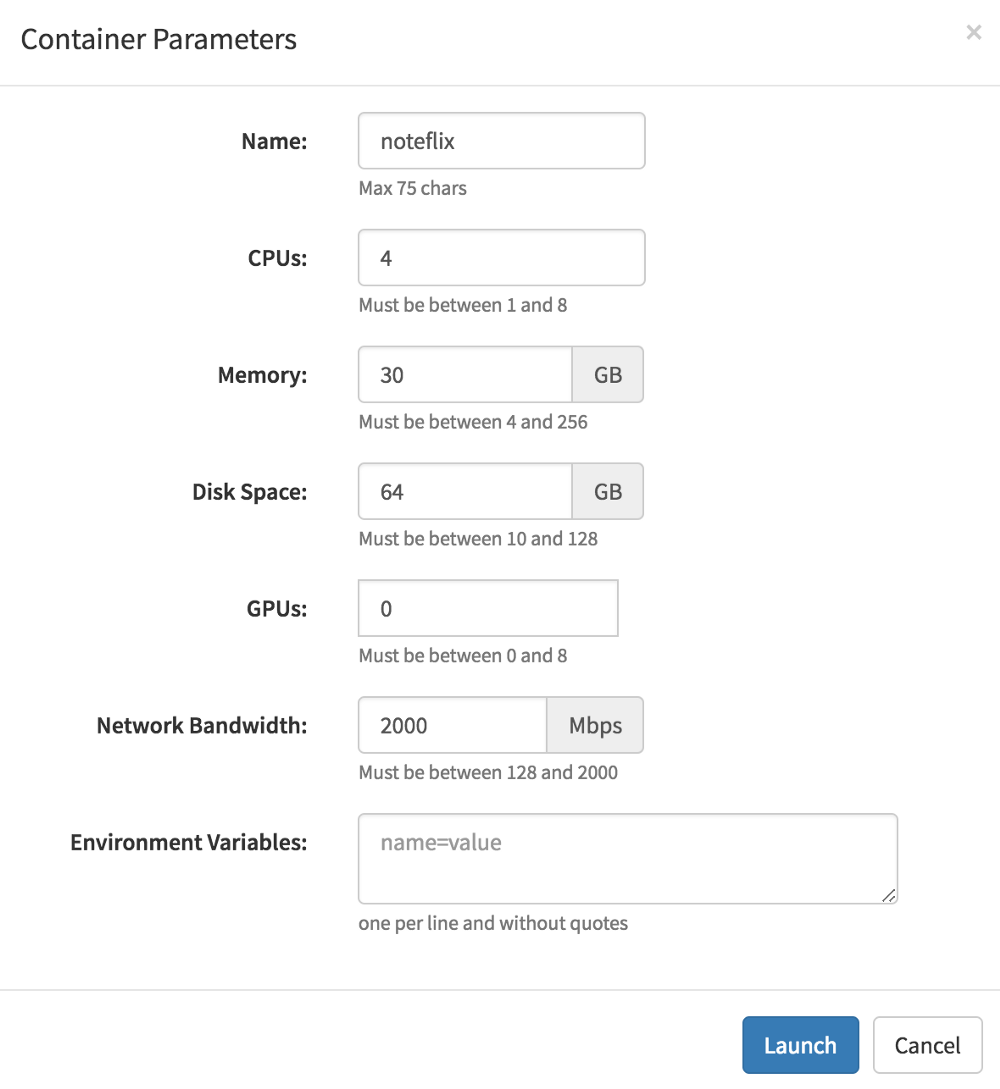
Управление вычислительными ресурсами сложная часть работы с данными. В Netflix для управления вычислительными ресурсами используют контейнерную архитектуру в AWS. Запросы, конвейеры, notebook и другие задания выполняются в контейнерах.
«Как рекомендовать музыку, которую почти никто не слушал. Доклад Яндекса», habr
Руководитель команды рекомендаций в Медиасервисах Даниил Бурлаков выступил на встрече «Яндекс изнутри» и рассказал о проблемах, которые возникают при работе с рекомендациями в Яндекс.Музыке.
Главные продукты Яндекс.Музыки — умные плейлисты и Яндекс.Радио, которые активно используются и развиваются.
Умные плейлисты

Плейлист дня — набор треков, который обновляется каждый день и доступен без интернета.
Дежавю — треки, которые пользователи никогда не слушали.
Премьера — подборка треков исполнителей, которые могут понравится слушателю.
Сложности формирования плейлистов
При создании рекомендаций существуют две серьезные проблемы:
- Холодные пользователи — только пришли на сервис и про них ничего не известно
- Холодный контент — треки, которые появились недавно или редкие песни.
Варианты решения проблем
Пользователь выбирает жанры и любимых исполнителей, а потом получает первый плейлист дня.

Сначала система ориентируется на среднего пользователя, а затем переходит к персонализации. Если трек не понравился — предлагает что-то другое. Так формируется персонализированный плейлист.

Эти два варианта в целом решают проблему холодных пользователей, но они не применимы к холодному контенту. Эту проблему можно решить с помощью SVD.

Результаты

«В Москве протестируют беспилотный трамвай. Мы поговорили с разработчиками автопилота», habr
Руководитель департамента разработки беспилотных транспортных средств в Cognitive Technologies Юрий Минкин рассказал о проекте беспилотного трамвая в Москве.
Как работает. Система использует 20 камер и 10 радаров, которые контролируют все зоны трамвая. Для того, чтобы система работала в любую погоду используют технологию data fusion — обрабатывает данные с камер и радаров одновременно.
О машинном зрении. Позволяет определять разные объекты — людей, светофоры, автомобили и другое разнообразие, которое обычно видит водитель.
О безопасности. Высокая технологичность трамвая дает возможность управлять трамваем электронно и получать информацию о состоянии всех систем. Атаковать трамвай невозможно — вся система находится внутри и не имеет входа снаружи. Радары помогут избежать атак изображений-обманок.
Что нужно, чтобы проект был реализован:
- тестирование различных ситуаций в городских условиях;
- доработка алгоритмов;
- сбор данных.
«Разработчик SearchFace о возможностях алгоритма», habr
Кейс компании, получившей иск «ВКонтакте», о том, как работает сервис и какие возможности он открывает.
Поиск в SearchFace выполняется по базе из 500 миллионов альтернатив. Системе нужно отличить человека от миллионов других. Главная задача, которую поставили перед собой создатели — поиск по искаженным картинкам.

Пример работы сервиса
Тестирование помогло понять, что сервис может искать по фотографиям:
- с низким разрешением;
- с необычным выражением лица и мимикой;
- где видна только часть лица;
- по детским фотографиям.
«Как научить машину понимать инвойсы и извлекать из них данные», habr
В блоге компании ABBYY рассказали, как с помощью машинного обучения извлекать данные из инвойсов.
Инвойс — документ, который предоставляется продавцом покупателю и содержит информацию о товарах и услугах, их количестве и цене. Обычный инвойс состоит из различных полей из заголовка и табличных данных.
.jpg)
Пример инвойса
Компании тратят миллионы человеко-часов на обработку инвойсов и расходуют до 40$ на работу с одним бумажным инвойсом. Развитие машинного обучения дало возможность извлекать данные с помощью нейронных сетей, что ускорят процесс получения информации и экономит финансы компании. В ABBYY разработали свой алгоритм работы с инвойсами:
.png)
Результаты использования машинного обучения:
- выросло качество извлечения данных;
- появилась возможность дообучать сеть на новых данных, что решило проблему разнообразия форм инвойсов;
- можно просто установить продукт и начать его использовать без программирования.
«Новый подход к пониманию мышления машин», habr
Редактор Хабра Вячеслав Голованов перевел интервью исследовательницы из Google Brain Бин Ким.
Бин Ким — специалист по «интерпретированному» машинному обучению. Совместно с коллегами из Google Brain она разработала систему TCAV (Testing with Concept Activation Vectors), которая позволяет задать ИИ вопрос и получить на него осмысленный ответ.
Читать еще: «Как сквозная аналитика помогает бизнесу»
Мнение автора и редакции может не совпадать. Хотите написать колонку для «Нетологии»? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.