Подготовили подборку полезных материалов по Data Science. Узнаете, как можно оптимизировать email-маркетинг с помощью Data Science, сколько зарабатывают статистик и Data Scientist, а также как проходит день маркетолога-аналитика.
«Что маркетологу нужно знать о Data Science», Blendo
В блоге сервиса Blendo поделились кейсом, как с помощью Data Science оптимизировать email-маркетинг. Также рассказали, что должен знать маркетолог для решения такой задачи.
Цели и метрики
Важно четко сформулировать цели и определиться с метриками для измерения эффективности этих целей. Для оптимизации email-рассылок, метриками могут быть open rate (открываемость писем), click rate (кликабельность) или показатели эффективности, для которых нужны данные из других отделов компании.
На метрики могут влиять как очевидные данные (например, демографические), так и те, что еще нужно выявить. Необходимо помнить, что грамотно поставленные вопросы — залог пользы от Data Science.
Работа исследователя данных полностью зависит от четко сформулированных целей и правильных вопросов.
Правила работы с данными
Данные — это контент и то, как люди с ним взаимодействуют. Маркетологу необходимо разбираться в данных: от этого зависят аналитические результаты.
Пример. У почтовой платформы Mailchimp обширная база данных, на основе которой можно получить множество идей, но все эти данные — результат пользовательской активности на платформе. Например, если стоит задача отфильтровать рассылки о выходе нового продукта и о новом посте в блоге, могут помочь такие действия, как добавление демографических данных о получателях и включение информации о типе рассылки в дополнительные поля или заголовки рассылки.
Data Scientist убирает лишнюю информацию, которая влияет на качество данных. От этого зависит вся аналитика — от простого дашборда до сложных моделей, объясняющих поведение клиента.
Придерживайтесь следующих правил:
- Будьте постоянными в действиях. Например, если выбрали определенный формат для заголовков, то всегда придерживайтесь его.
- Обеспечьте полноту данных. При возможности свяжите корпоративные инструменты друг с другом. И в дальнейшем учитывайте фактор совместимости текущего инструментария и потенциального как один из ключевых.
На что обратить внимание
Очевидные данные всего лишь вершина айсберга. В датасете может быть много неочевидной информации, которую поможет найти Data Scientist.
Не стоит недооценивать также сложность технической инфраструктуры, необходимой для реализации задач. Вряд ли компания будет работать с сервисом, который не предоставляет API для извлечения данных.
Но инфраструктура данных также может накладывать определенные ограничения на цели. Например, есть задача получать аналитические уведомления в режиме реального времени, а данные могут обрабатываться лишь раз в сутки.
Маркетологу необходимо наладить коммуникацию с исследователями данных и техническим персоналом.
Кейс
Задача. Оптимизировать email-рассылки на платформе Mailchimp. Для оценки результата будет проанализирован показатель open rate, чтобы выяснить, что повышает вероятность открытия письма получателем.
Вводные от Mailchimp:
- цепочка событий для каждой рассылки, которая идентифицирует пользователей, открывших письмо;
- временная отметка отправки рассылки;
- электронные адреса получателей;
- тип рассылки, закодированный в заголовке (например, пост в блог, объявление о новом продукте) или в другом настраиваемом поле.
Что можно извлечь из этих данных:
- Выяснить, в какое время — рабочее или личное — было получено письмо. В этом поможет временная отметка и информация о местоположении каждого получателя.
- Классифицировать email-адреса на корпоративные и личные. В помощь — сами адреса и несколько простых правил.
- Определить тип письма как пост в блоге или анонс о продукте.
Что нужно сделать
- Выгрузить данные из Mailchimp. Чтобы Data Scientist всегда имел доступ к актуальным данным, необходимо настроить их автоматическое извлечение через фиксированные промежутки времени и сохранение в базе данных.
- Получить подмножество данных из базы данных.
- Разобрать и отфильтровать данные для поиска неочевидной информации.
- Проанализировать информацию и зафиксировать результаты.
В зависимости от размера компании первые два шага выполняет Data Engineer или Data Scientist, который работает с корпоративной инфраструктурой или с внешними аналитическими инструментами. Остальные действия выполняет Data Scientist. Когда он сделает заключение по результатам анализа, следует автоматизировать шаги 1-4, что снова потребует привлечения Data Engineer.
Полученный результат будет напрямую связан с вопросами, которые задавались изначально. Например, если Data Scientist применил логистическую регрессию, чтобы понять, как указанные параметры влияют на открываемость писем, у него, скорее всего, получится что-то подобное:
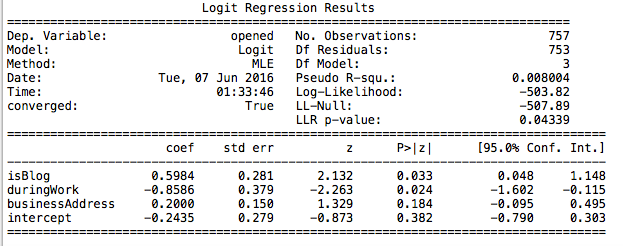
На основании этого Data Scientist сформирует отчет, в котором будет примерно следующее:
- тип e-mail адреса не влияет на степень открываемости;
- письма в рабочее время имеют негативный эффект;
- письма с анонсами нового поста в блоге люди открывают намного чаще.
«В чем разница между исследователем данных и статистиком?», habr
Компания Otus перевела статью о различиях статистика и Data Scientist в навыках, инструментах, зарплате и карьерных возможностях.

Чем занимаются Data Scientist и статистик
Data Scientist оценивает большие объемы данных компании (предыдущие и текущие) для принятия оптимальных бизнес-решений. Находит инсайты и выявляет показатели, которые могут быть полезны для реализации маркетинговой стратегии.
Статистик оценивает данные в поисках закономерностей, на базе которых строит статистические и математические модели. Собранные данные используются в разных областях, в том числе в инженерном деле, науке и бизнесе. В частности бизнесу помогают отслеживать или прогнозировать тенденции для принятия решений.
Что должны уметь и знать
| Исследователь данных | Статистик |
|---|---|
| SQL: работа с базами данных и программирование | Глубокие знания теории вероятности и индуктивной статистики |
| Программирование на R или Python | Умение работать с цифрами |
| Платформа Hadoop, Hive или Pig | Аналитические способности |
| Машинное обучение и искусственный интеллект | Навыки письменной и устной коммуникации |
| Визуализация данных | Хорошие навыки межличностного общения |
| Неструктурированные данные | |
| Знание принципов ведения бизнеса | |
| Навыки коммуникации |
Какими инструментами должны владеть
| Исследователь данных | Статистик |
|---|---|
| R — программный пакет для статистических вычислений и их визуализации | SPSS (Statistical Package for the Social Sciences) — статистическое ПО в области исследования поведения человека |
| Python — популярный язык программирования для разработки бэкендов, производства компьютеров, математических задач, создания скриптов для систем | R — программный пакет, который активно используется в исследованиях поведения человека и других областях |
| Julia — язык программирования для высокопроизводительных вычислений | MatLab (Mathworks) — платформа для аналитики и программирования |
| Tableau — один из лучших инструментов визуализации данных в секторе бизнес-аналитики | Microsoft Excel |
| QlikView — аналитический инструмент, одна из основных платформ для обнаружения корпоративных данных | Статистические инструменты GraphPad Prism и Minitab |
Как различаются зарплаты
Исследователь данных — универсальный специалист, который отвечает на важные бизнес-вопросы. Эта специальность более востребована: исследователь данных в США получает в 1,6 раза больше, чем статистик ($118 709 против $75 069).
Каким может быть карьерный путь
Специалист по анализу данных
- Исследователь данных.
- Специалист по обработке данных.
- Аналитик.
Статистик
- Специалист по статистическим методам.
- Прикладной статистик.
- Старший специалист по статистике.
- Руководитель отдела статистики.
- Частный консультант по статистике.
«Построение поведенческих воронок на языке R на основе данных, полученных из Logs API Яндекс.Метрики», habr
Руководитель отдела аналитики Netpeak Алексей Селезнев подробно — с кодами, функциями, скриншотами — описал порядок действий для построения и визуализации воронки продаж на языке R с помощью дополнительных пакетов rym, funneljoin и ggplot2.
Запрос данных из Logs API Яндекс.Метрики: пакет rym
Согласно официальной справке Яндекс, главная функция Logs API — получение и самостоятельная обработка статистических данных для решения уникальных аналитических задач. Для работы с этим API потребуется установить R-пакет rym — интерфейс для взаимодействия с Яндекс.Метрикой.
Для построения поведенческой воронки нужно загрузить таблицу о всех визитах на сайте и обработать данные для анализа.
Из API Яндекс.Метрики запрашивается список доступных счётчиков и настроенных целей: переход в корзину, переход к оплате, страница «спасибо за заказ», клик по кнопке «телефон».
Из Logs API запрашиваются необходимые данные о визитах:
- ym:s:visitID — идентификатор визита;
- ym:s:clientID — идентификатор пользователя на сайте;
- ym:s:date — дата визита;
- ym:s:goalsID — идентификатор целей, достигнутых за данный визит;
- ym:s:lastTrafficSource — источник трафика;
- ym:s:isNewUser — первый визит посетителя.
Построение воронки: пакет funneljoin
Цель funneljoin — упростить анализ воронки поведения пользователей. Среди примеров: найти людей, которые впервые посетили сайт и зарегистрировались на нем, а также узнать промежуток времени между этими событиями; выделить пользователей, которые просмотрели информацию о товаре и положили его в корзину в течение двух дней.
Постобработка данных из Logs API
В первую очередь необходимо привести данные из Logs API к правильному формату. Удобнее всего с этим помогают справиться пакеты tidyr и dplyr из библиотеки tidyverse.
Далее формируются новые таблицы:
- first_visits — даты первых сеансов по всем новым пользователям;
- cart — даты добавления товаров в корзину;
- orders — заказы.
Информация об идентификаторе пользователя и дате совершения события остается в новых таблицах.
Наиболее полезные типы воронок
Шаги по воронке
Logs API отдаёт данные обо всех событиях в одной таблице. Для создания последовательности действий удобно использовать функции funnel_start() и funnel_step().
Funnel_start помогает задать первый шаг воронки и принимает пять аргументов:
- tbl — таблица событий;
- moment_type — первое событие в воронке;
- moment — имя столбца, в котором содержится название события;
- tstamp — название столбца с датой совершения события;
- user — имя столбца с идентификаторами пользователей.
При помощи функции funnel_step можно строить воронки с любым количеством шагов.
Вишенка на торте — summarize_funnel(). Функция, которая позволяет вывести процент пользователей, перешедших с прошлого шага на следующий, а также процент пользователей, прошедших от первого шага до каждого последующего.
Визуализация воронки: пакет ggplot2
Ggplot2 — мощный инструмент для визуализации данных; один из наиболее популярных R-пакетов, установленный более миллиона раз.
В основе инструмента лежит грамматика построения графики. Визуализация строится слой за слоем, аналогично работе в Photoshop.
Визуализация общей воронки
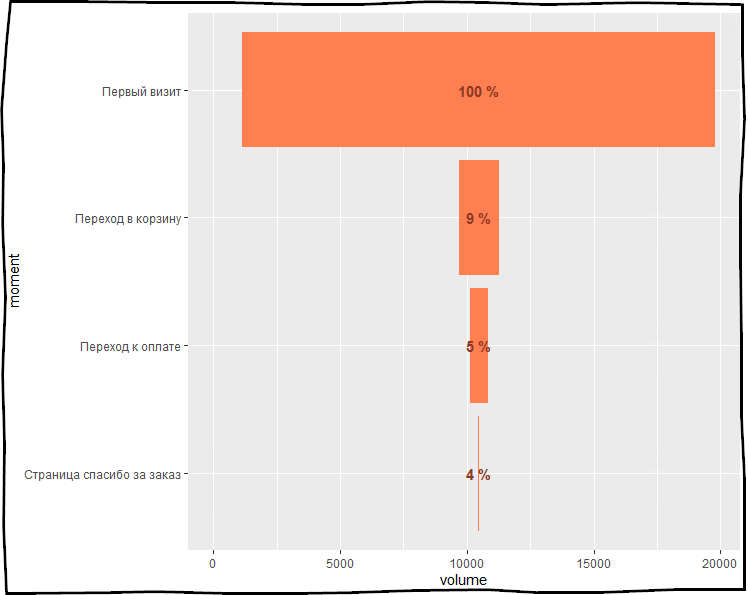
Визуализация воронки в разрезе каналов трафика
Для анализа воронки интересно смотреть ее в различных разрезах — например, в разрезе каналов. Для такого разреза подойдет функция lapply — ускоренный аналог циклов в R. С помощью lapply воронки строятся по каждому из интересующих каналов. Объединить результат поможет функция bind_rows.
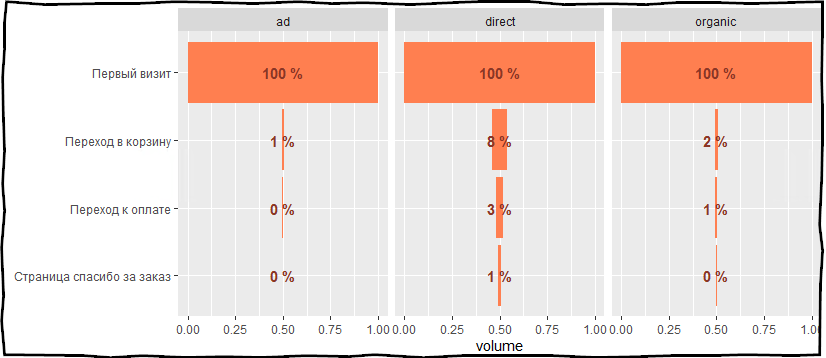
Чеклист: что нужно сделать для построения воронки продаж с помощью языка R
- Настроить в Яндекс.Метрике отслеживание ключевых событий на сайте.
- Установить язык R и среду разработки R Studio.
- Установить пакеты rym, funneljoin и ggplot2.
- Получить данные из Яндекс.Метрики с помощью пакета rym.
- Построить поведенческие воронки в нужных разрезах при помощи пакета funneljoin.
- Визуализировать результат с помощью пакета ggplot2.
Указанный метод поможет построить более сложные воронки продаж, если к данным из Яндекс.Метрики добавить данные о продажах из CRM, 1С или из других источников. Например, оплаты заказов, повторные покупки и кросс-продажи.

редакция нетологии
- Принимайте решения на основе data-driven подхода
- Прогнозируйте поведение клиентов
- Выстраивайте сквозную аналитику в компании с нуля
- Визуализируйте результаты
«Один день из жизни маркетолога-аналитика», Towards Data Science
Руководитель отдела маркетинговой аналитики Инстаграма Крис Доусет рассказал о многогранности профессии маркетолога-аналитика. Крис показал это на примере своего рабочего дня.
Большинство не имеет представления, чем занимается маркетолог-аналитик. Кто-то ограничивает функционал этого специалиста отслеживанием статистики посещений, кликов и конверсий, другие называют так специалистов по маркетинговым исследованиям, и есть даже те, кто предъявляет маркетологам-аналитикам претензии к рекламе.
Среди задач маркетолога-аналитика:
- Работа с простыми SQL-запросами и полнофункциональными алгоритмами машинного обучения.
- Взаимодействие с данными экосистемы: анализ продуктовых направлений, выявление связи между характеристиками продукта, демографическими данными и культурными тенденциями — прикладная вычислительная социальная наука.
Разноплановая роль маркетолога-аналитика влечет за собой определенные последствия для компании: например, на основе аналитических отчетов принимаются многомиллионные решения.
Регулярные задачи практикующего маркетолога-аналитика
SQL-запросы.
Почта (дважды в день).
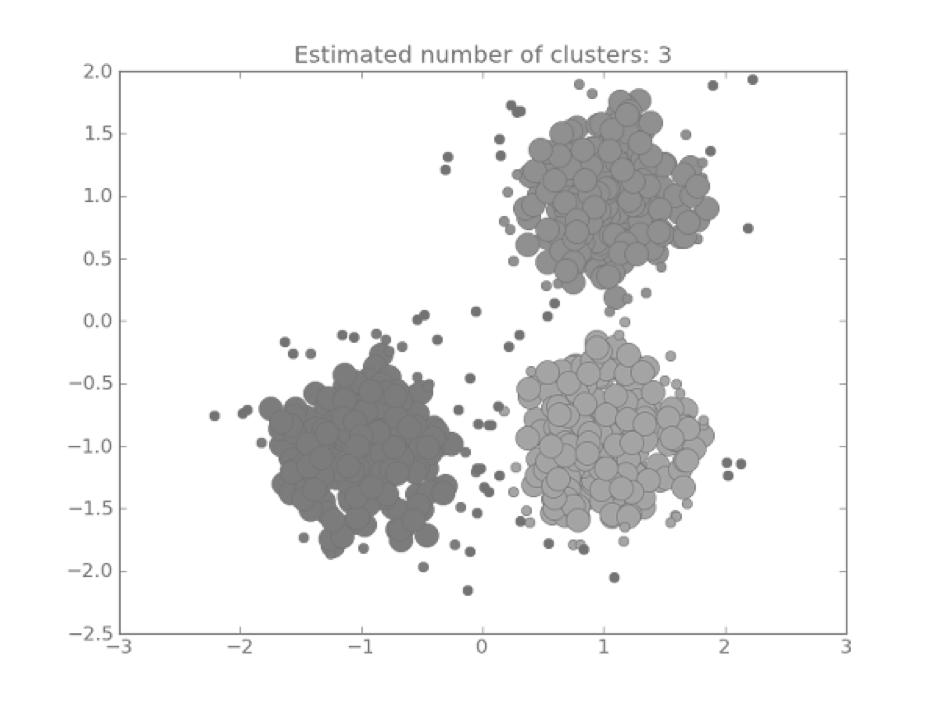
Кластерный анализ. Кластеризация — задача машинного обучения, которая помогает обнаружить «естественные» группы пользователей. Например, целевую аудиторию «ниже среднего» — пользовательские кластеры, проранжированные от низких к высоким по ряду метрик.
Мозговые штурмы с коллегами-маркетологами. Обсуждение потенциальных аудиторий, KPI, стратегий и бюджета.
Анализ дашбордов и трендов. В распоряжении четыре автоматизированных дашборда, которые охватывают демографические показатели, эффективность маркетинговой деятельности, сегментацию по регионам и контрольные показатели. Дважды в месяц тренды на базе информации из дашбордов рассылают командам.
Анализ результатов кампаний. Для измерения эффективности рекламных активностей используют показатели тестовых и контрольных групп. Рекламу видит только тестовая группа. С помощью SQL и R маркетолог-аналитик сравнивает поведение обеих групп и определяет, есть ли значительная разница между группами по продуктовым метрикам. Результаты заносят в сводный отчет и калибровочную базу данных.
Встреча с продуктовыми аналитиками. Продуктовые аналитики отвечают за глубокое понимание трендов и нюансов специфических категорий продукта, а также за создание и поддержку основных таблиц данных для категорий продукта. Маркетологи-аналитики изучают взаимосвязи и взаимодействия во всех категориях, а также измеряют маркетинговое влияние на поведение пользователей на базе инсайтов продуктовых аналитиков.
Обсуждение создания системы машинного обучения с Data Engineer. Речь идет о системе, которая автоматизирует сессии маркетинговых кампаний для возможности тестирования с поддержкой масштабирования. Техногики объединяются и обсуждают алгоритмы, переводят R-код на Python и выясняют, какие базы данных необходимо настроить.
Прогнозирование ROI крупной маркетинговой кампании. Задача маркетолога-аналитика — оценить, стоит ли инвестировать крупные средства и человеческие ресурсы в кампанию. Поэтому он тщательно проверяет потенциальный охват, прогноз кликабельности (CTR) и примерную стоимость действия (CPA).
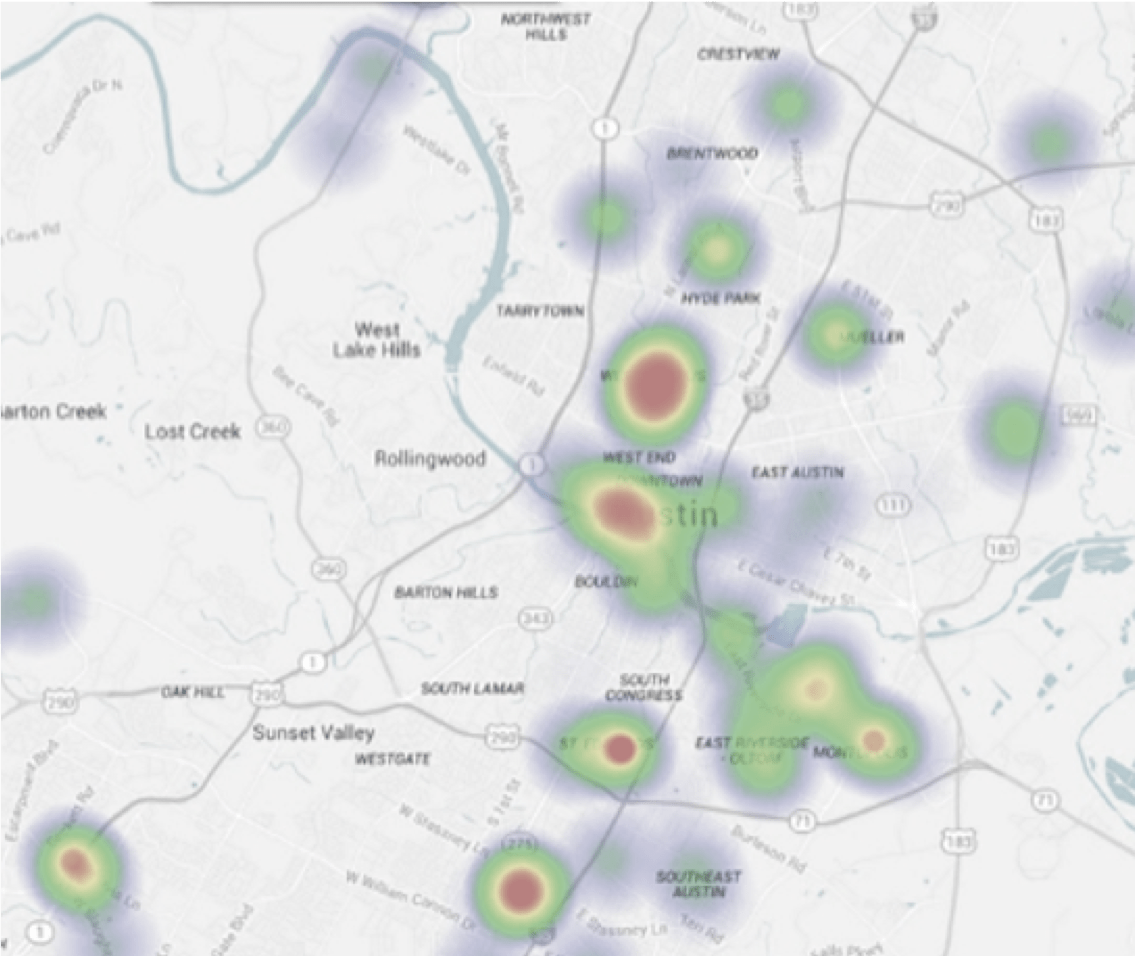
Составление географической карты активности. Коллеги работают над программой для всплывающих окон в городах Великобритании. Города выбрали, осталось выяснить, где именно в городах необходимо запускать всплывающее окно. Для этого нужно определить локации, где в обеденное время будет много пешеходов. Для этого автор использует данные о местоположении и картографический функционал в R (Leaflet API). Это позволит создать тепловые карты перемещений пешеходов и выявить топовые локации.
Составление плана по оценке маркетинговой активности. Раздел с оценкой, в котором указаны KPI, второстепенные метрики, цели, аудитория, география и оценочный подход, является обязательным для всех планов. Если в рамках кампании планируется что-то исследовать, то в план добавляется соответствующая секция. В Инстаграме сильно развита культура тестирования гипотез, поэтому аналитики и исследователи (если применимо) вовлечены в создание маркетинговых планов.
Обсуждение поведенческих трендов в Японии с региональным менеджером по маркетингу. Раз в два месяца автор общается с региональными менеджерами для представления информации по интерактивным дашбордам, а также для обсуждения их планов и видения. С небольшими датасетами можно использовать Tableau, для больших наборов данных автор использует встроенный инструмент дашборда.
Запуск SQL-запросов на ночь. Когда люди уходят с работы, становится доступно больше серверных ресурсов. Это имеет значение, поскольку маркетологи-аналитики работают с таблицами из миллиардов строк данных.
Заключение
Работа маркетолога-аналитика выходит далеко за рамки кликов и конверсий. Это смесь из дашбордов, алгоритмов, кодов и внутренних консультаций. Профессия маркетолога-аналитика совмещает в себе данные, разнообразие и влияние.
«Руководство по R с недавних пор самая цитируемая неакадемическая публикация в академических работах», habr
Речь идет о суммировании цитирования всех версий руководства «R: a language and environment for statistical computing» («R: язык и среда для статистических вычислений») в списке литературы и примечаний библиографической базы данных Web of Science. В базе Scopus, которую часто упоминают вместе с Web of Science, это руководство на 2-м месте.
Топ-10 категорий Web of Science и Scopus, в которых цитируют R-руководство (количество упоминаний)
- Экология (35 805).
- Науки об окружающей среде (16 597).
- Междисциплинарные науки (14 681).
- Эволюционная биология (10 806).
- Науки о растениях (10 384).
- Зоология (10 301).
- Морская биология — пресноводные (10 136).
- Сохранение биоразнообразия (9 071).
- Генетика наследственности (8 535).
- Статистическая вероятность (6 898).
Психолог и Data Scientist Евгений Томилов так аргументировал важность языка в науке: «R позволяет создавать воспроизводимые протоколы исследований, включающие в себя данные и их обработку. В условиях тотальных фальсификаций и острой необходимости в увеличении воспроизводимости и правдоподобии научных работ, использование этого инструмента является как минимум полезным, а как максимум этичным».
Однако R достаточно сложный язык для освоения, поэтому некоторые ученые пользуются альтернативным решением: при поиске в базе Google Scholar и по данным на 2018 год, статистическое ПО SPSS используется в полтора раза чаще для написания академических работ.
Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.