





Легко ли это? Я попробовал.
Алексей Кузьмин, директор разработки и работы с данными ДомКлик, преподаватель факультета «Аналитика и Data Science» в Нетологии, перевёл статью Rahul Agarwal о том, как работают методы Монте-Карло с цепями Маркова для решения проблем с большим пространством состояний.
Каждый, кто связан с Data Science, хоть раз слышал о методах Монте-Карло с цепями Маркова (MCMC). Иногда тема затрагивается во время изучения байесовской статистики, иногда — при работе с такими инструментами, как Prophet.
Но MCMC трудно понять. Всякий раз, читая об этих методах, я замечал, что суть MCMC скрыта в глубоких слоях математического шума, и за этим шумом её тяжело разобрать. Мне пришлось потратить много часов, чтобы разобраться в этой концепции.
В этой статье — попытка объяснить методы Монте-Карло с цепями Маркова доступно, так, чтобы стало понятно, для чего они используются. Я остановлюсь ещё на нескольких способах использования этих методов в моём следующем посте.
Итак, начнём. MCMC состоит из двух терминов: Монте-Карло и Марковские цепи. Поговорим о каждом из них.
Монте-Карло

Методы Монте-Карло получили своё название от казино Монте-Карло в Монако. Во многих карточных играх нужно знать вероятность выиграть у дилера. Иногда вычисление этой вероятности может быть математически сложным или трудноразрешимым. Но мы всегда можем запустить компьютерную симуляцию, чтобы много раз воспроизвести всю игру и рассматривать вероятность как количество побед, разделённое на количество сыгранных игр.
Это всё, что вам нужно знать о методах Монте-Карло. Да, это просто несложная техника моделирования с причудливым названием.
Марковские цепи

Поскольку термин MCMC состоит из двух частей, нужно ещё понять, что такое цепи Маркова. Но прежде, чем перейти к Марковским цепям, немного поговорим о Марковских свойствах.
Предположим, есть система из M-возможных состояний и вы переходите из одного состояния в другое. Пусть пока вас ничего не сбивает с толку. Конкретный пример подобной системы — погода, которая меняется от жаркой к холодной и умеренной. Другой пример — фондовый рынок, который прыгает от «медвежьего» к «бычьему» и состоянию стагнации.
Марковское свойство говорит о том, что для данного процесса, который находится в состоянии Xn в конкретный момент времени, вероятность Xn + 1= k (где k — любое из M-состояний, в которое процесс может перейти) зависит только от того, каково это состояние в данный момент. А не о том, как оно достигло нынешнего состояния.
Говоря математическим языком, можем записать это в виде следующей формулы:
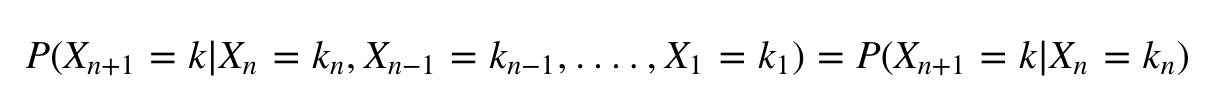
Для наглядности: вы не заботитесь о последовательности состояний, которые рынок принимал, чтобы стать «бычьим». Вероятность того, что следующее состояние будет «медвежьим», определяется только тем фактом, что рынок в настоящее время находится в «бычьем» состоянии. Это также имеет смысл на практике.
Процесс, обладающий Марковским свойством, называется Марковским процессом. Из-за чего же важна Марковская цепь? Из-за своего стационарного распределения.
Что такое стационарное распределение
Я попытаюсь объяснить стационарное распределение, рассчитав его для приведённого ниже примера. Предположим, у вас есть Марковский процесс для фондового рынка, как показано ниже.
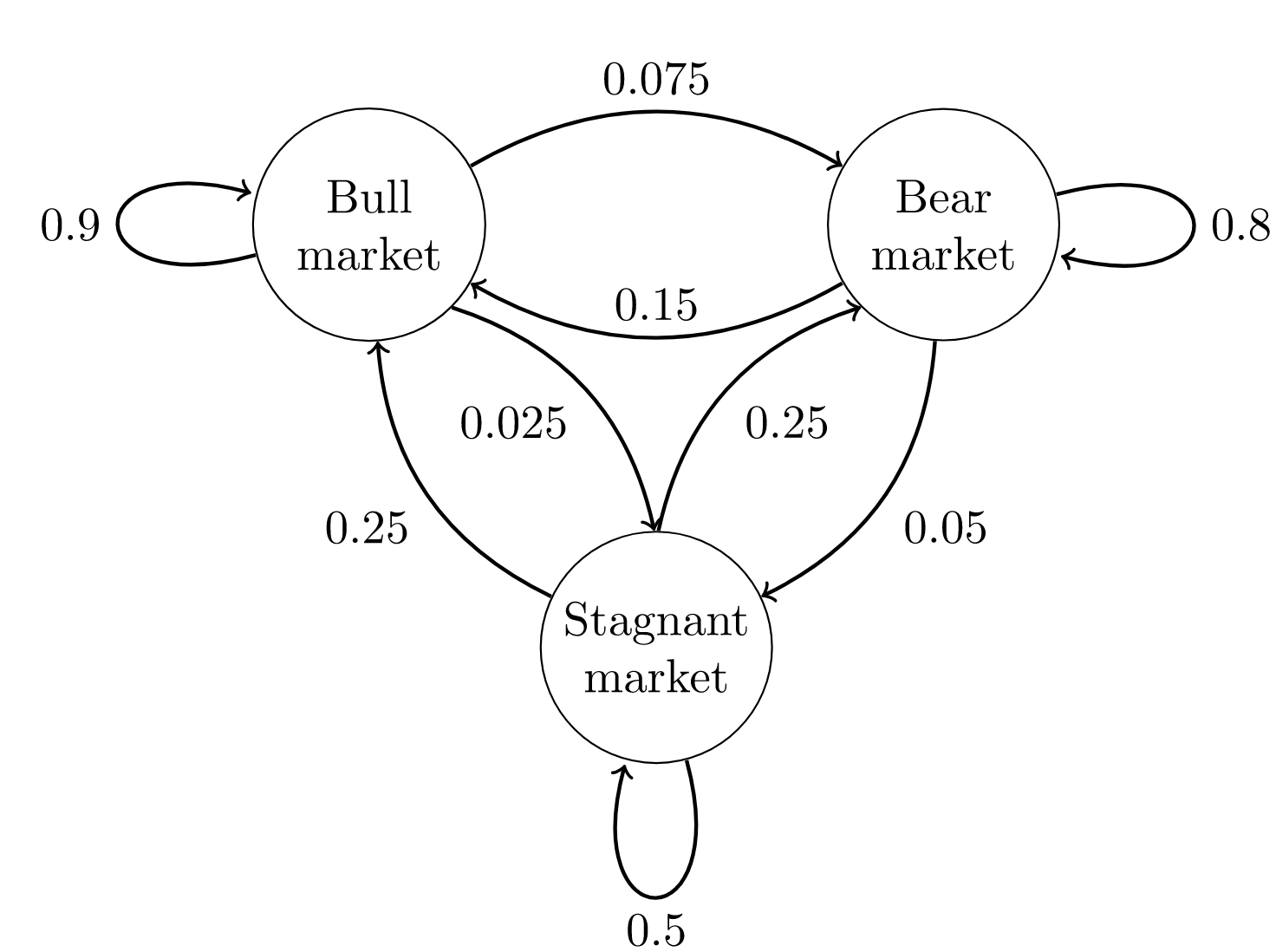
У вас есть матрица переходных вероятностей, которая определяет вероятность перехода из состояния Xi в Xj.

В приведённой матрице переходных вероятностей Q вероятность того, что следующим состоянием будет «бык», учитывая текущее состояние «бык» = 0,9; вероятность того, что следующее состояние будет «медвежьим», если текущее состояние «бык» = 0,075. И так далее.
Что ж, давайте начнём с какого-то определённого состояния. Наше состояние будет задаваться вектором [бык, медведь, стагнация]. Если мы начнём с «медвежьего» состояния, вектор будет таким: [0,1,0]. Мы можем вычислить распределение вероятности для следующего состояния, умножив вектор текущего состояния на матрицу переходных вероятностей.
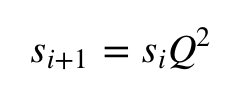
Заметьте, что вероятности дают в сумме 1.
Следующее распределение состояний можно найти по формуле:
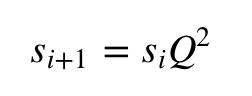
И так далее. В конце концов, вы достигнете стационарного состояния, в котором состояние стабилизируется:
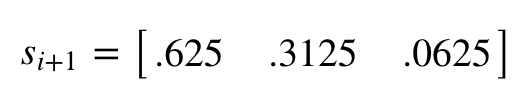
Вы можете получить стационарное распределение при помощи следующего кода:
Q = np.matrix([[0.9,0.075,0.025],[0.15,0.8,0.05],[0.25,0.25,0.5]]) init_s = np.matrix([[0, 1 , 0]]) epsilon =1 while epsilon>10e-9: next_s = np.dot(init_s,Q) epsilon = np.sqrt(np.sum(np.square(next_s - init_s))) init_s = next_s
print(init_s) ------------------------------------------------------------------ matrix([[0.62499998, 0.31250002, 0.0625 ]])
Вы также можете начать с любого другого состояния — достигнете того же стационарного распределения. Измените начальное состояние в коде, если хотите в этом убедиться.
Теперь мы можем ответить на вопрос, почему же стационарное распределение так важно.
Стационарное распределение важно, потому что с его помощью можно определять вероятность системы быть в определенном состоянии в случайное время.
Для нашего примера можно сказать, что в 62,5% случаев рынок будет в «бычьем» состоянии, 31,25% — в «медвежьем» и 6,25% — в стагнации.
Интуитивно вы можете рассматривать это как случайное блуждание по цепи.

Вы находитесь в определенной точке и выбираете следующее состояние, наблюдая распределение вероятностей следующего состояния с учётом текущего состояния. Мы можем посещать некоторые узлы чаще, чем другие, основываясь на вероятностях этих узлов.
Именно таким образом на заре интернета Google решил проблему поиска. Проблема заключалась в сортировке страниц, в зависимости от их важности. В Google решили задачу, используя алгоритм Pagerank. В алгоритме Google Pagerank следует рассматривать состояние как страницу, а вероятность страницы в стационарном распределении — как ее относительную значимость.
Теперь перейдём непосредственно к рассмотрению методов MCMC.
Что такое методы Монте-Карло с цепями Маркова (MCMC)
Прежде чем ответить, что же такое MCMC, позвольте задать один вопрос. Мы знаем о бета-распределении. Мы знаем его функцию плотности вероятностей. Но можем ли мы взять выборку из этого распределения? Вы можете придумать способ, как это сделать?

MCMC даёт возможность выбрать из любого распределения вероятностей. Это особенно важно, когда нужно сделать выборку из апостериорного распределения.
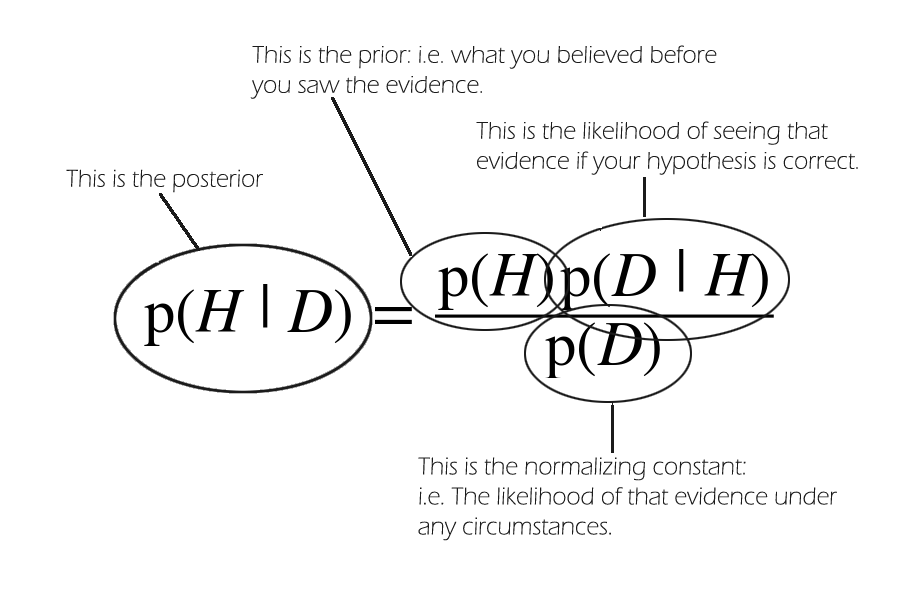
Например, нужно сделать сэмпл из апостериорного распределения. Но легко ли вычислить апостериорную компоненту вместе с нормирующей постоянной (evidence)? В большинстве случаев можно найти их в виде произведения правдоподобия и априорной вероятности. Но рассчитать нормирующую постоянную (p (D)) не получится. Почему? Разберёмся подробнее.
Предположим, H принимает только 3 значения:
p(D) = p(H=H1).p(D|H=H1) + p(H=H2).p(D|H=H2) + p(H=H3).p(D|H=H3)
В таком случае p(D) подсчитать легко. А что, если значение H непрерывно? Получилось бы ли рассчитать это так же легко, особенно если H принимала бесконечные значения? Для этого пришлось бы решить сложный интеграл.
Мы хотим сделать случайный отбор из апостериорного распределения, но также хотим считать p(D) константой.
Википедия пишет:
Методы Монте-Карло с цепями Маркова — это класс алгоритмов для выборки из распределения вероятностей, основанный на построении цепи Маркова, которая в качестве стационарного распределения имеет желаемый вид. Состояние цепи после ряда шагов затем используется в качестве выборки из желаемого распределения. Качество выборки улучшается с увеличением количества шагов.
Разберёмся на примере. Допустим, нужна выборка из бета-распределения. Его плотность:
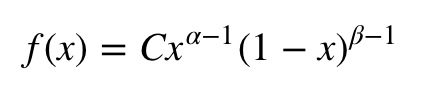
где C — нормирующая постоянная. На самом деле это некоторая функция от α и β, но я хочу показать, что для выборки из бета-распределения она не нужна, поэтому мы примем ее за константу.
Задача с бета-распределением действительно сложная, если не сказать практически неразрешимая.
В действительности вам, вероятно, придётся работать с более сложными функциями распределения, а иногда вы не будете знать нормирующие постоянные.
Методы MCMC облегчают жизнь, предоставляя алгоритмы, которые могли бы создать цепь Маркова, которая в качестве стационарного распределения имеет бета-распределение, учитывая, что мы можем выбирать из равномерного распределения (что относительно просто).
Если начнём со случайного состояния и перейдём к следующему состоянию на основе некоторого алгоритма несколько раз, мы в конечном итоге создадим цепь Маркова, у которой в качестве стационарного распределения будет бета-распределение. А состояния, в которых мы окажемся через долгое время, могут использоваться как выборка из бета-распределения.
Один из таких MCMC-алгоритмов — алгоритм Метрополиса-Гастингса.
Алгоритм Метрополиса-Гастингса

Интуиция:
Так, в чём же цель?
Интуитивно понятно, что мы хотим ходить по некоторой кусочной поверхности (нашей цепи Маркова) таким образом, чтобы количество времени, которое мы проводим в каждом местоположении, было пропорционально высоте поверхности в этом месте (желаемая плотность вероятности, из которой хотим сделать выборку).
Так, например, мы хотели бы провести вдвое больше времени на вершине холма высотой 100 метров, чем на соседнем 50-метровом холме. Хорошо, что мы можем сделать это, даже если не знаем абсолютных высот точек на поверхности: все, что нужно знать, это относительные высоты. Например, если вершина холма A в два раза выше вершины холма B, то мы бы хотели провести в A вдвое больше времени, чем на B.
Существуют более сложные схемы предложения новых мест и правил их принятия, но основная идея заключается в следующем:
- Выбрать новое «предложенное» местоположение.
- Выяснить, насколько выше или ниже это местоположение находится по сравнению с текущим.
- Остаться на месте или переместиться в новое место с вероятностью, пропорциональной высотам мест.
Цель MCMC — выборка из некоторого распределения вероятностей без необходимости знать его точную высоту в любой точке (не нужно знать C).
Если процесс «блуждания» настроен правильно, вы можете убедиться, что эта пропорциональность (между проведенным временем и высотой распределения) достигнута.
Алгоритм:
Теперь давайте определим и опишем поставленную задачу более формально. Пусть s = (s1, s2,…, sM) — желаемое стационарное распределение. Мы хотим создать цепь Маркова с таким стационарным распределением. Начнем с произвольной цепи Маркова с M-состояниями с матрицей перехода P, так, что pij представляет вероятность перехода из состояния i в j.
Интуитивно мы знаем, как бродить по цепи Маркова, но цепь Маркова не имеет требуемого стационарного распределения. Эта цепь имеет некоторое стационарное распределение (которое нам не нужно). Наша цель — изменить способ, которым мы блуждаем по цепи Маркова, чтобы цепь имела желаемое стационарное распределение.
Для этого следует:
- Начать со случайного начального состояния i.
- Случайным образом выбрать новое предполагаемое состояние, посмотрев на вероятности перехода в i-й строке матрицы перехода P.
- Вычислить меру, называемую вероятностью принятия решения, которая определяется как: aij = min (sj.pji / si.pij, 1).
- Теперь подбросить монетку, которая приземляется на поверхность орлом с вероятностью aij. Если выпадет орел, принять предложение, то есть перейти к следующему состоянию, иначе — отклонить предложение, то есть остаться в текущем состоянии.
- Повторить много раз.
После большого количества испытаний эта цепь будет сходиться и иметь стационарное распределение s. Затем мы можем использовать состояния цепи как выборку из любого распределения.
Проделывая это для выборки бета-распределения, единственный раз, когда приходится использовать плотность вероятности, — это поиск вероятности принятия решения. Для этого делим sj на si (то есть нормирующая постоянная C сокращается).
Выборка из бета-распределения

Теперь перейдём к проблеме выборки из бета-распределения.
Бета-распределение — непрерывное распределение на [0,1] и может иметь бесконечные значения на [0,1]. Предположим, что произвольная цепь Маркова P с бесконечными состояниями на [0,1] имеет переходную матрицу P такую, что pij = pji = все элементы в матрице.
Нам не нужна Матрица P, как мы увидим позже, но я хочу, чтобы описание проблемы было максимально приближено к алгоритму, который мы предложили.
- Начать со случайного начального состояния i, полученного из равномерного распределения на (0,1).
- Случайным образом выбрать новое предполагаемое состояние, посмотрев на вероятности перехода в i-й строке матрицы перехода P. Предположим, мы выбрали другое состояние Unif (0,1) в качестве предполагаемого состояния j.
- Вычислить меру, которую называют вероятностью принятия решения:
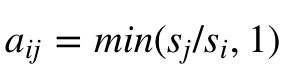
Что упрощается до:
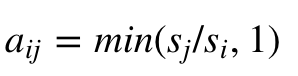
Так как pji=pij, и где
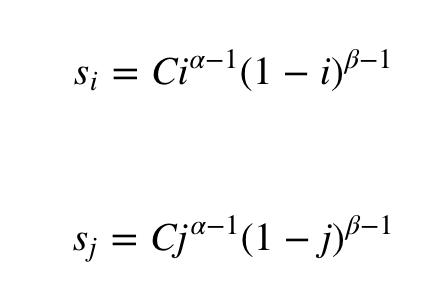
- Теперь подбросим монетку. С вероятностью aij выпадет орел. Если выпадет орел, тогда стоит принять предложение, то есть перейти в следующее состояние. В противном случае стоит отвергнуть предложение, то есть остаться в прежнем состоянии.
- Повторить испытание много раз.
Код:
Пора перейти от теории к практике. Напишем на Python наш бета-образец.
impo rt rand om # Lets define our Beta Function to generate s for any particular state. We don't care for the normalizing constant here def beta_s(w,a,b): return w**(a-1)*(1-w)**(b-1) # This Function returns True if the coin with
probability P of heads comes heads when flipped. def random_coin(p): unif = random.uniform(0,1) if unif>=p: return Falst else: return True # This Function runs the MCMC chain for Beta Distribution. def beta_mcmc(N_hops,a,b): states = [] cur = random.uniform(0,1) for i
in range(0,N_hops): states.append(cur) next = random.uniform(0,1) ap = min(beta_s(next,a,b)/beta_s(cur,a,b),1) # Calculate the acceptance probability if random_coin(ap): cur = next return states[-1000:] # Returns the last 100 states of the chain
Сверим результаты с фактическим бета-распределением.
impo rt num py as np import pylab as pl import scipy.special as ss %matplotlib inline pl.rcParams['figure.figsize'] = (17.0, 4.0) # Actual Beta PDF. def beta(a, b, i): e1 = ss.gamma(a
+ b) e2 = ss.gamma(a) e3 = ss.gamma(b) e4 = i ** (a - 1) e5 = (1 - i) ** (b - 1) return (e1/(e2*e3)) * e4 * e5 # Create a function to plot Actual Beta PDF with the Beta Sampled from MCMC Chain. def plot_beta(a, b): Ly = [] Lx = [] i_list = np.mgrid[0:1:100j] for i in
i_list: Lx.append(i) Ly.append(beta(a, b, i)) pl.plot(Lx, Ly, label="Real Distribution: a="+str(a)+", b="+str(b)) pl.hist(beta_mcmc(100000,a,b),normed=True,bins =25, histtype='step',label="Simulated_MCMC: a="+str(a)+", b="+str(b)) pl.legend() pl.show() plot_beta(0.1,
0.1) plot_beta(1, 1) plot_beta(2, 3)
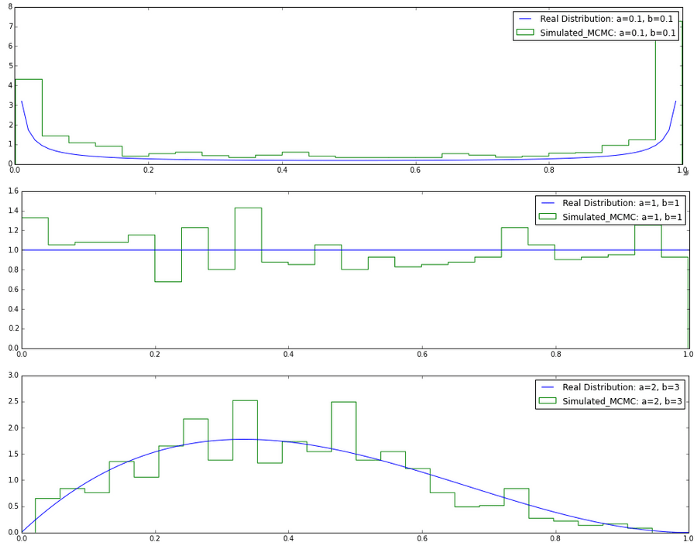
Как видно, значения очень похожи на бета-распределение. Таким образом, сеть MCMC достигла стационарного состояния
В приведенном выше коде мы создали бета-сэмплер, но та же концепция применима к любому другому распределению, из которого хотим сделать выборку.

Алексей кузьмин
Директор разработки и работы с данными ДомКлик
- Научитесь строить и обучать предиктивные модели с помощью алгоритмов машинного обучения и нейросетей
- Сможете находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы
Выводы
Это был большой пост. Поздравляю, если дочитали его до конца.
В сущности, методы MCMC могут быть сложными, но они предоставляют нам большую гибкость. Вы можете сделать выборку из любой функции распределения, используя выбор посредством MCMC. Обычно эти методы используют для выборки из апостериорных распределений. Вы также можете использовать MCMC для решения проблем с большим пространством состояний. Например, в задаче о рюкзаке или для расшифровки.
ЧИТАТЬ ТАКЖЕ
? Почему опасно опираться только на статистическую значимость
Мнение редакции и автора может не совпадать. Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.