





Что такое сиамские сети, чем различается машинное и глубокое обучение, какие навыки помогут построить карьеру в Data Science — об этом в нашем свежем дайджесте.
 Обучение в онлайн-университете: курс «Big Data с
нуля»
Обучение в онлайн-университете: курс «Big Data с
нуля»
«Распознавание лиц с помощью сиамских сетей», habr
В блоге компании «Инфосистемы Джет» на Хабре опубликовали перевод статьи о том, что такое сиамские сети и как они помогают распознавать лица.

Сиамская нейросеть — простой и популярный алгоритм однократного обучения — для каждого класса берут только один учебный пример. Сиамскую сеть используют в приложениях, где в каждом классе не так много единиц данных.
Автор статьи создает на основе сиамской нейросети модель распознавания лиц, которую научит определять, когда лица одинаковые, а когда нет.
Для начала нужно скачать датасет AT&T Database of Faces и распаковать архив:
Каждая папка содержит 10 фотографий, снятых с разных ракурсов. Например, содержимое папки s1:
А это содержимое папки s13:
Нужно подавать парные значения с маркировками. Возьмите две любые фотографии из одной папки и пометьте как «подлинную» пару (genuine). Потом нужно взять две фотографии из других папок и пометить как «ложную» пару (imposite):

Подробнее о том, как создать модель распознавания лиц, читайте в статье.
Обучение в онлайн-университете: курс «Python для работы с данными»
«4 Python библиотеки для интерпретируемого машинного обучения», Proglib
Proglib рассказали, какие библиотеки можно использовать для интерпретации и объяснения моделей машинного обучения.
Yellowbrick
Yellowbrick — Python-библиотека и расширение пакета scikit-learn, предоставляющая визуализации для моделей машинного обучения. Если привыкли работать с scikit-learn, то разобраться будет просто, а рабочий процесс покажется знакомым.
ELI5
ELI5 — библиотека визуализации для отладки моделей машинного обучения и объяснения прогнозов. Работает с самыми различными инструментами машинного обучения на Python.
LIME
LIME может интерпретировать предсказания алгоритмов машинного обучения. Взаимодействует с scikit-learn и поддерживает объяснение единичных прогнозов из диапазона классификаторов.
MLxtend
Эта библиотека содержит множество вспомогательных функций. Охватывает: классификаторы стекинга, голосования, оценку модели и выделение признаков.
Обучение в онлайн-университете: профессия «Машинное обучение»
«Словарь: чем различаются машинное и глубокое обучение», Rusbase
Если до сих пор путаете машинное и глубокое обучение — эта статья для вас.
Под искусственным интеллектом обычно понимают способность машины выполнять, свойственные человеку функции — рассуждение, обучение, совершенствование на основе опыта, решение определенных задач.
Рынок искусственного интеллекта активно развивается и растет:
Что такое машинное обучение
Машинное обучение — класс методов для решения задач искусственного интеллекта.
Можно разделить на три группы:
1. Контролируемое машинное обучение, или обучение с учителем: применяется для прогнозирования спроса на продукт, предотвращения мошенничества с банковскими картами.
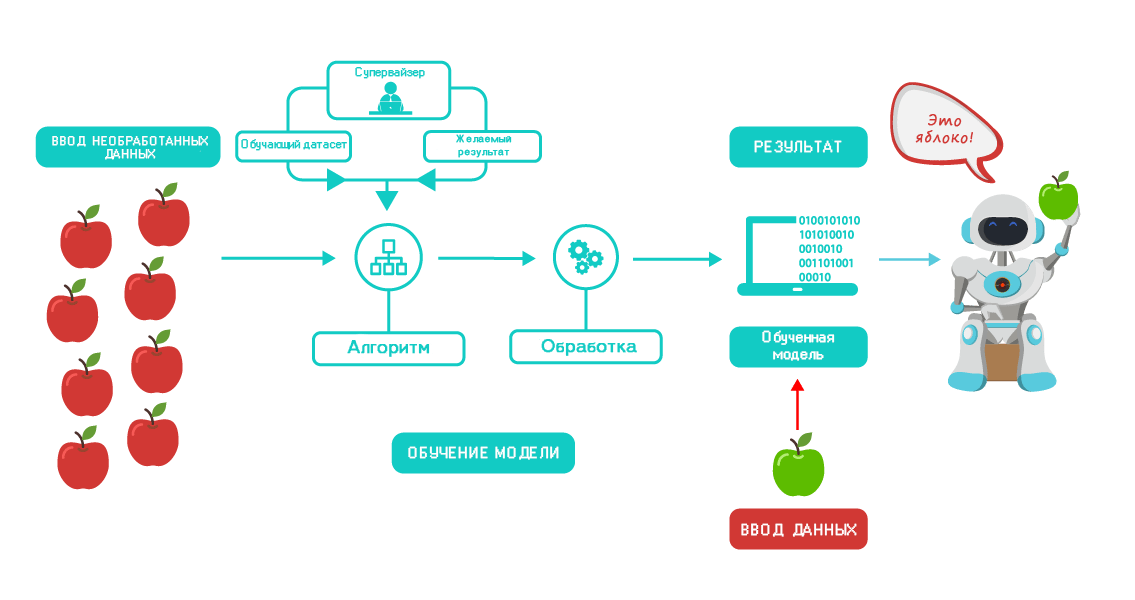
2. Неконтролируемое машинное обучение, или обучение без учителя: применяется при сегментации работников по вероятности профессионального выгорания, для рекомендации фильмов людям со схожими вкусами.
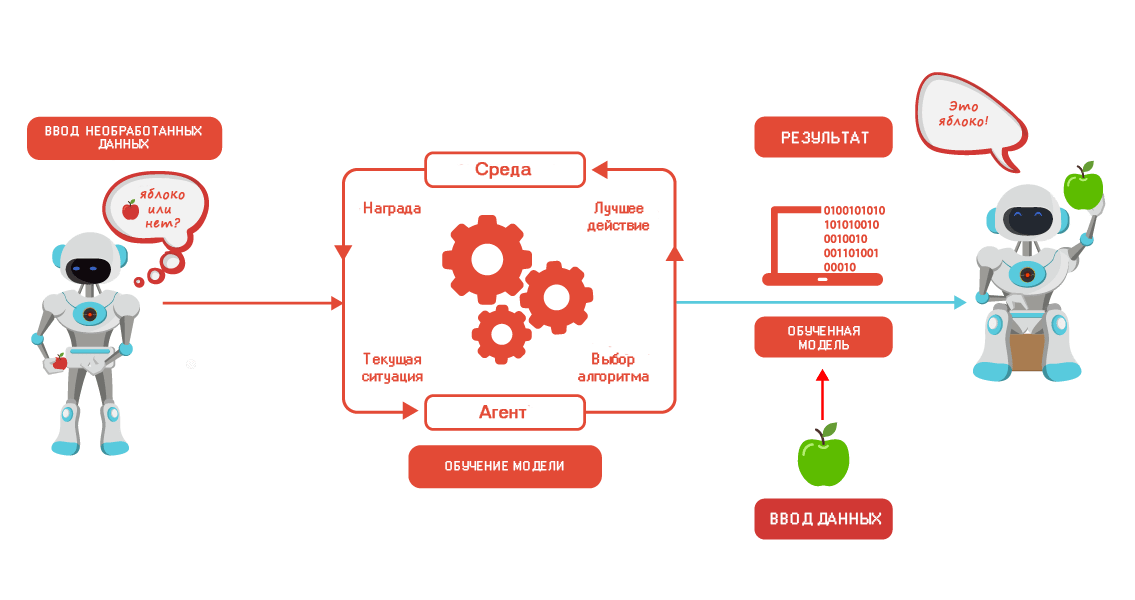
3. Обучение с подкреплением: применяется для обучения промышленных роботов, оптимизации вождения беспилотных автомобилей.
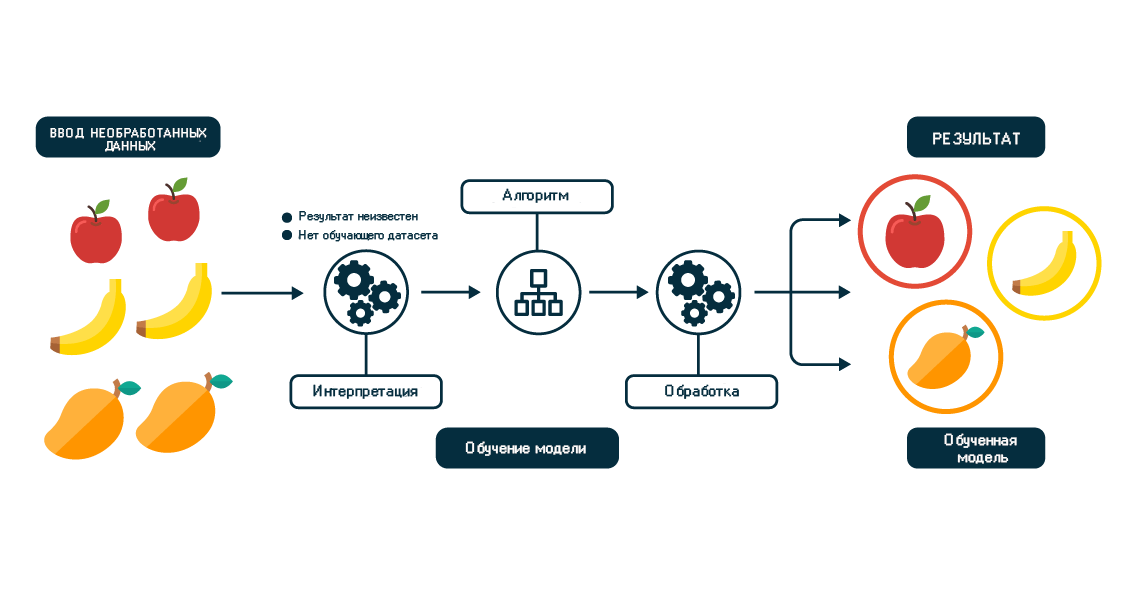
4. Частичное обучение, или обучение с частичным привлечением учителя: применяется для речевой аналитики, классификации веб-страниц.
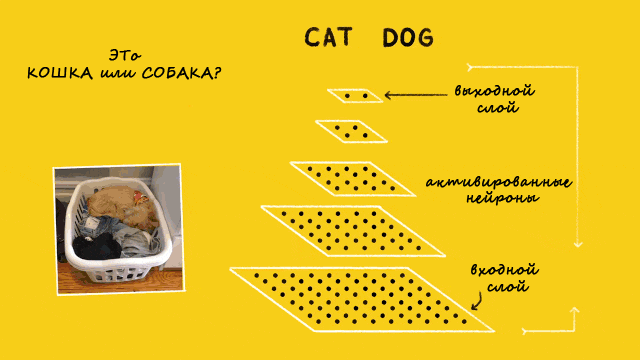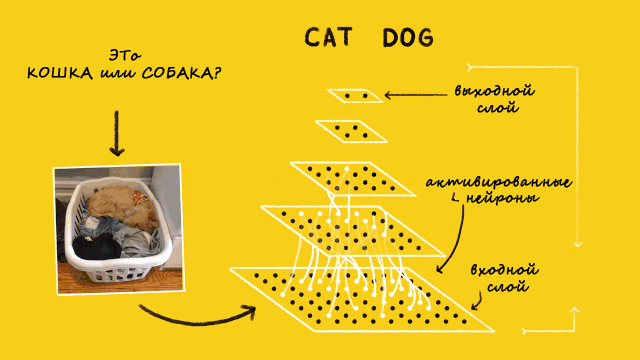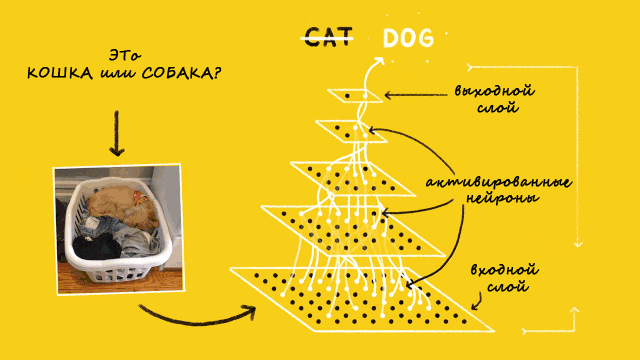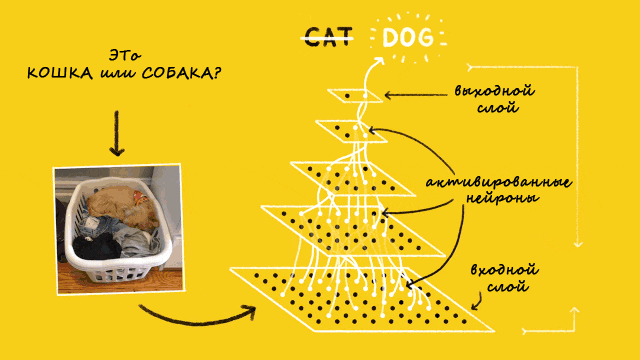
Что такое глубокое обучение
Глубокое обучение — набор методов, в которых используются нейронные сети с большим количеством нейронов и слоев для извлечения признаков.
«Как я построила прогнозную модель call-центра, чтобы их звонки не бесили пользователей», habr
Бывает, что ложитесь спать, а вам звонят и предлагают какой-то продукт, — это ужасно бесит.
Дата-сайентист Наталья Галанова в блоге Skyeng на Хабре рассказала, какую прогнозную модель разработала, чтобы выстроить хорошие отношения с клиентами и повысить конверсию.
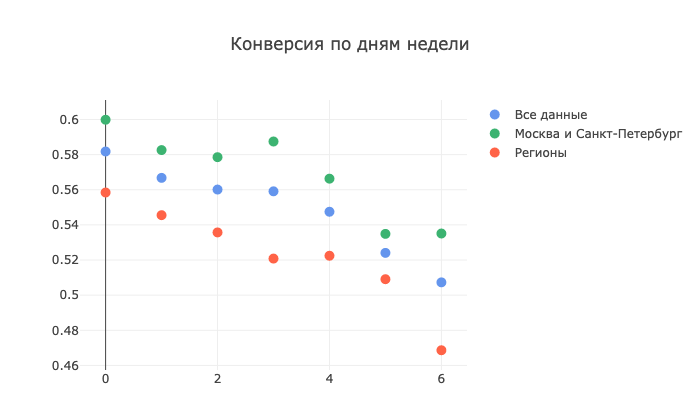
1. Автор считала, что звонить клиентам лучше в будние дни, кроме пятницы. Для этого она построила график конверсии по дням недели. Предположение подтвердилось:
А если разложить звонки по часам:
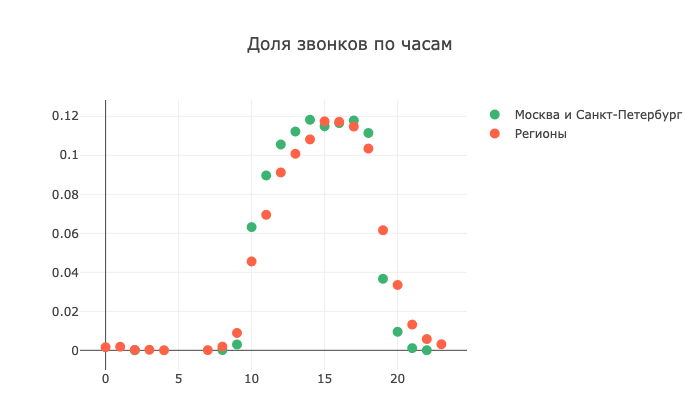
2. Проанализировав данные, Наталья вывела следующее время для звонков:
- понедельник: с 13 до 17;
- вторник: с 12 до 18;
- среда: с 11 до 12 и с 15 до 17;
- четверг: с 10 до 17;
- пятница: с 10 до 12;
- суббота: с 16 до 18;
- воскресенье: с 13 до 14 и с 18 до 19.
3. Всю модель можно резюмировать так:
- вероятность дозвона рассчитывается по каждому ученику и для каждого часа суток и дня недели;
- в соответствии с часовым поясом ученика выбирается время с 9 до 20 часов для каждого дня недели;
- перед сохранением время сдвигается на московское время, так как дозвон будет осуществляться именно в московском часовом поясе;
- результаты сохраняются в БД.
«Применение машинного обучения и Data Science в промышленности», habr
На Хабре опубликовали список блокнотов и библиотек ML и Data Science для разных сфер: недвижимость, питание, бухгалтерский учет, сельское хозяйство, банковское дело и страхование, биотехнологии и наука, строительная техника и инженерия, экономика и образование и других. Полезная штука, которую нужно добавить в закладки!

«Шесть навыков, которые выведут вашу карьеру в Data Science на новый уровень», habr
На Хабре опубликовали статью опытного дата-сайентиста Женевьев Хэйс о том, какие навыки нужно развивать, чтобы добиться успехов в сфере Data Science.
Автор делит все навыки на три группы:
- Моделирование и статистика: статистическое моделирование и развертывание моделей.
- Инженерия данных (Data Engineering) и программирование: работа с базами данных.
- Коммуникабельность и профессионализм: предоставление информации по результатам анализа данных, руководство и наставничество, коммуникабельность.
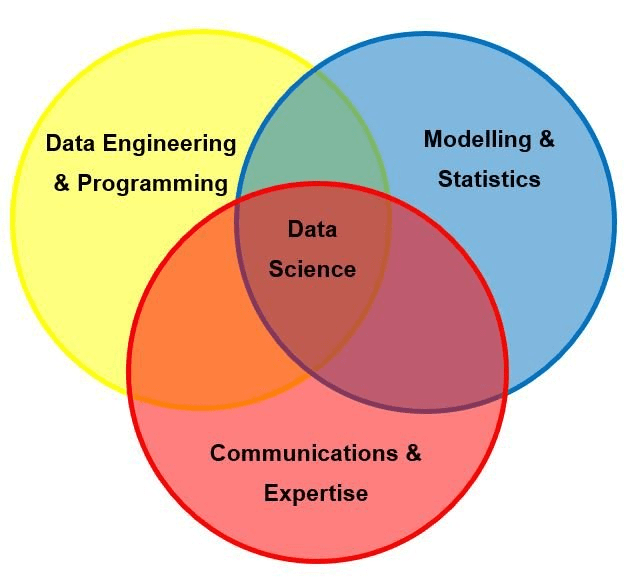
Женевьев считает, что в первую очередь нужно развивать коммуникабельность — это ценят работодатели. К тому же, начинающим специалистам нужно подтянуть знания в статистическом моделировании. А если вы хотите стать управленцем от науки о данных — подтяните навыки управленца.
Читать еще: «Создание модели распознавания лиц с
использованием глубокого обучения на языке Python»

редакция блога нетологии
Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.